





















































![[기초] GIT 교육 자료](https://cdn.slidesharecdn.com/ss_thumbnails/git-160711233512-thumbnail.jpg?width=560&fit=bounds)






















Ad
More Related Content
What's hot (20)
Similar to Understanding Kubernetes Scheduling - CNTUG 2024-10 (20)




![[k8s] Kubernetes terminology (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/k8skubernetesterminology1-230513211357-e2d31a79-thumbnail.jpg?width=560&fit=bounds)













Ad
Recently uploaded (20)




















Ad
Understanding Kubernetes Scheduling - CNTUG 2024-10
- 3. Agenda kube-scheduler What is the role of kube-scheduler? Scheduling Framework What is the process in kube-scheduler? kube-scheduler-simulator What is the result of our scheduling strategy?
- 5. Control Plane API-server The central interface that manages and exposes the cluster’s data. etcd A distributed, reliable key-value store that provides persistent data storage for cluster state. kube-controller-manager Executes control loops to maintain the desired state of cluster components. kube-scheduler Determines which node for deploying pods.
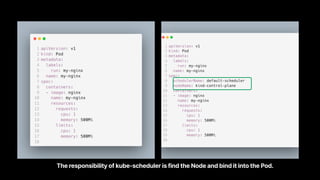
- 6. Pod Manifest What kind of properties would infect scheduling?
- 7. Image with description First thing Add a quick description of each thing, with enough context to understand what’s up. Second thing Keep ‘em short and sweet, so they’re easy to scan and remember. The responsibility of kube-scheduler is find the Node and bind it into the Pod.
- 8. “How does Kubernetes schedules workloads evenly across nodes in a cluster?” Adam · No Where
- 9. Scheduling Balanced Scheduling Imbalanced Scheduling
- 10. Pod Manifest What kind of properties would infect scheduling?
- 11. containers.resources.requests The Node must have such allocatable resources.
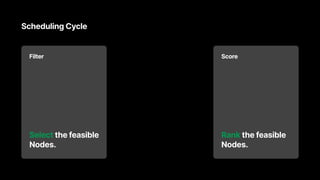
- 13. Scheduling Cycle Filter Select the feasible Nodes. Score Rank the feasible Nodes.
- 14. containers.resources.requests The Node must have such allocatable resources.
- 15. NodeResourcesFit in Filter and Score Filter Select nodes with for the pod. sufficient resources Score Rank the feasible nodes based on . resource availability
- 16. NodeResourcesFit in Filter and Score Filter Select nodes with for the pod. sufficient resources Score Rank the feasible nodes based on . resource availability
- 17. Cloud charge cross-zone Traffic Cloud charges the traffic between different Zone.
- 18. “The primary Database deploy on Zone A. In Kubernetes, how to schedule the workload to Zone-A?” Adam · No Where
- 19. “NodeSelector!” Adam · No Where
- 20. NodeSelector Kubernetes scheudules the workload into Zone A. MUST
- 22. Zone A outage Zone A Zone B Zone C
- 23. Schedule with Nodeselector Filter Select the feasible Nodes which is in Zone A. Score Rank the feasible Nodes.
- 24. Failover When anything works fine Schedule the workload into Zone A. When something got wrong. Schedule the workload into Zone B. Zone A Zone A Zone B Zone B Zone C Zone C
- 25. NodeAffinity Kubernetes schedules the workload into Zone A. PREFER
- 26. Schedule with NodeAffinity Filter Select the feasible Nodes Score Rank prefer Zone A,but Zone B is fine the feasible Nodes,
- 27. Schedule with NodeAffinity Filter Select in Zone A the feasible Nodes Score Rank prefer Zone A. the feasible Nodes,
- 28. Happy Disaster Some product go viral, increase the loading of workload rapidly.
- 29. Problem Even we deploy the HPA and clusterautoscaler, but the scaled node might takes minutes to join cluster.
- 30. “How to scale workload ASAP?” Adam · No Where
- 32. Over-provisoning Proactive Node standby Schedule low priority Pod on Proactive Node Proactive Node services High priority Pod preempts low priority Pod on Proactive Node Node A Node A Node B Node B Node C Node C High Priority Pod Log Priority Pod
- 33. Scheduling Cycle Filter Select the feasible Nodes. Score Rank the feasible Nodes.
- 34. Scheduling Cycle Filter Select the feasible Nodes. Post-filter Preemption runs here. Score Rank the feasible Nodes. If feasible Nodes NO
- 36. “Sounds wonderful, but how to test it?” Adam · No Where
- 37. Three problem about test scheduling Cost If you want to build a test environment for testing scheduling strategy, it might be expensive. Test at Large Scale Private Cloud might not have enough machines, even in Public Cloud, you might need some time to build a large cluster. Trouble shooting The scheduling would like to know the all nodes in the Cluster, complicated Scheduling strategy is hard to test.
- 39. Three problem about test scheduling Cost kss can test scheduling without resources. Test at Large Scale kss can test scheduling at Large Scale easy. Trouble shooting kss provides debuggable scheduler, it logs all result in stages about Scheduling Framework.
- 40. Demo Using kube-scheduler-simulator to verify the over-provisioning pattern. Scale out Node → 10 Deploy Backend x 40 Deploy low-priority-class and low-priority-pod x 12 Observe LPP Pending Simulate the behavior of clusterautoscaler:Scale out Node -> 13 Observe LPP, it should be deployed to the Proactive Node Simulate the behavior of HPA:Scale out backend 40 → 52 Observe Backend preempt LPP
- 41. “I heard every stages in Scheduling Framework is an extension point, how can we extend it?” Adam · No Where
- 43. Now about extending scheduler Scheduler Profile If default scheduler fits your needs, but you want some custom. For example, the parameter of some Plugin, or high weight of specific Plugin. Scheduler Extender bad performance, bad error handling. Plugins You need to build your scheduler with the custom plugins.
- 44. Demo Using kube-scheduler-simulator to verify the custom plugin. Enable the custom plugin in KubeSchedulerConfiguration Deploy new Pod Verify the score of custom plugin
- 45. Trend about scheduler Descheduler Obey the scheduling policy after deployment. Evict the pod before the resources usage hit the limits. Batch Job for ML Batch Job for ML is different from normal. Kueue and QueueHint. kube-scheduler-wasm- extension Extend kube-scheduler with WASM.
- 46. Takeaway Understand Scheduling gives us more choices about actions.
- 47. Bonus
- 48. Three Common Misconception First pod.containers.resources.requests only works during scheduling. Second Usage above won’t cause any problem. pod.containers.resources.limits Third Only Memory would cause OOMKilled.
- 49. Three Common Misconception First pod.containers.resources.requests only works during scheduling. The requests.cpu would affect the cgroup. The limits.cpu would cause the CPU throttling. The GC Thread might not GC completely because the CPU throttling, it might trigger OOMKilled. Second Usage above won’t cause any problem. pod.containers.resources.limits Third Only Memory would cause . OOMKilled