







![事前学習-Masked Language Model
• 入力の一部を[MASK]トークンに置き換えて、それを予測する
タスク
• My dog is hairy. -> My dog is [MASK].
• [MASK]部以外を利用して[MASK]を予想する
10](https://image.slidesharecdn.com/20200916dlhirata-200923021013/85/Unified-Vision-Language-Pre-Training-for-Image-Captioning-and-VQA-10-320.jpg)
![モデル – 入出力
• 入力:画像の領域(N個)、単語(T個)の埋め込みベクトル(d
次元) [CLS], [SEP], [STOP]の特殊トークン3つ
• 画像の領域
•𝑅𝑖:i番目の領域の特徴量ベクトル
•𝐶𝑖:i番目の領域のクラス分布
•𝐺𝑖:i番目の領域の座標に関するベクトル
•𝑊は学習すべき重み
• 単語𝑦𝑡
d次元の埋め込みベクトル
• 特殊トークン
•[CLS]:入力の開始 [SEP]:画像と文を分ける [STOP]: 入力の
終了
12](https://image.slidesharecdn.com/20200916dlhirata-200923021013/85/Unified-Vision-Language-Pre-Training-for-Image-Captioning-and-VQA-12-320.jpg)
![モデル – 入出力
• 本当の入力は前ページのものを合わせた
𝐻0 = [𝑟 𝐶𝐿𝑆 , 𝑟1, 𝑟2, … , 𝑟 𝑁, 𝑦 𝑆𝐸𝑃 , 𝑦1, 𝑦2, … , 𝑦 𝑇, 𝑦 𝑆𝑇𝑂𝑃 ]
• 以下の式でTransformer Blockを計算
𝐻 𝑙 = 𝑇𝑟𝑎𝑛𝑠𝑓𝑜𝑚𝑒𝑟(𝐻 𝑙−1)
• 出力:
𝐻 𝐿 = ℎ 𝑟 𝐶𝐿𝑆
, ℎ 𝑟1
, … , ℎ𝑦 𝑆𝐸𝑃 , ℎ𝑦1, … , ℎ𝑦 𝑇, ℎ𝑦 𝑆𝑇𝑂𝑃
13](https://image.slidesharecdn.com/20200916dlhirata-200923021013/85/Unified-Vision-Language-Pre-Training-for-Image-Captioning-and-VQA-13-320.jpg)

![各タスクの解き方
• 画像キャプション
1. 画像の領域を切り出し、(1)式でベクトル化
2. 画像と[MASK]をモデルに入力し、[MASK]を予測
3. 画像と最初の単語の予測結果、[MASK]をモデルに入
力し、2つ目の[MASK]を予測
4. これを[STOP]が予測されるまで繰り返す
※λ=1.0に設定
15](https://image.slidesharecdn.com/20200916dlhirata-200923021013/85/Unified-Vision-Language-Pre-Training-for-Image-Captioning-and-VQA-15-320.jpg)
![各タスクの解き方
• VQA
• 答えの候補となるクラスをあらかじめ定めておき、多
クラス分類として定式化
• [CLS]と[SEP]に対する出力を使い、クラス分類問題
を解く
※λ=0に設定
16](https://image.slidesharecdn.com/20200916dlhirata-200923021013/85/Unified-Vision-Language-Pre-Training-for-Image-Captioning-and-VQA-16-320.jpg)




![実験と結果 - 画像情報の保持に関する実験
• Faster R-CNNの出力
• 領域の特徴量ベクトル、領域のラベル
•ラベルを予測するpretext taskを追加する[1]
•ラベル分布を入力としてとらえる(本手法)
22
[1] Tan, H., and Bansal, M. 2019. Lxmert: Learning crossmodality encoder
representations from transformers. arXiv preprint arXiv:1908.07490.](https://image.slidesharecdn.com/20200916dlhirata-200923021013/85/Unified-Vision-Language-Pre-Training-for-Image-Captioning-and-VQA-22-320.jpg)



















![SSII2021 [OS2-02] 深層学習におけるデータ拡張の原理と最新動向](https://cdn.slidesharecdn.com/ss_thumbnails/os2-03latest-210610045610-thumbnail.jpg?width=560&fit=bounds)
![[DL輪読会]One Model To Learn Them All](https://cdn.slidesharecdn.com/ss_thumbnails/dljp20170714ono-170714005853-thumbnail.jpg?width=560&fit=bounds)





![[DL輪読会]MUTAN: Multimodal Tucker Fusion for Visual Question Answering](https://cdn.slidesharecdn.com/ss_thumbnails/dlreadingyokota20171222-171222003255-thumbnail.jpg?width=560&fit=bounds)





Ad
More Related Content
What's hot (11)
Similar to Unified Vision-Language Pre-Training for Image Captioning and VQA (20)




![[DL輪読会] MoCoGAN: Decomposing Motion and Content for Video Generation](https://cdn.slidesharecdn.com/ss_thumbnails/0911mocogan-170911121936-thumbnail.jpg?width=560&fit=bounds)




Ad
More from harmonylab (20)




















Ad
Unified Vision-Language Pre-Training for Image Captioning and VQA
- 1. 1 北海道大学調和系工学研究室 B4 平田航大 Unified Vision-Language Pre- Training for Image Captioning and VQA
- 2. 論文情報 • タイトル • Unified Vision-Language Pre-Training for Image Captioning and VQA • 著者 • Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Jason J. Corso, Jianfeng Gao • 学会 • AAAI 2020 2
- 3. 概要 • Vision-Language タスクにおける統一的なモデルUnified Vision-Language Pre-trainingモデルを提案 • Understanding(e.g. VQA)とgeneration(e.g. 画像 キャプション)タスクを統一的なモデルで扱える • EncoderとDecoderでも統一的なTransformerを使用 3
- 4. タスクの紹介 • 画像キャプション 画像を説明する文章を生成 する 4 • VQA 画像とそれに関する質問分を 入力とし、答えを返す 引用元:「日本語による画像キャプ ション自動生成AIを作ったので丁寧 に解説します!」 https://qiita.com/oreyutarover/items/6 eb0e12ba0d169a480df 引用元:"VQA: Visual Question Answering“(Antol et al. 2015)
- 6. 背景 • これまでの研究では・・・ • EncoderとDecoderで異なるモデルを用いるものが一 般的 • Understanding taskとGeneration taskでモデルが 異なることが一般的 →これらを統一したモデルの提案 6
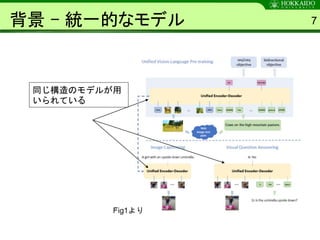
- 7. 背景 - 統一的なモデル 7 同じ構造のモデルが用 いられている
- 8. 関連研究:Transformer • 提案論文: • “Attention Is All You Need” (Vaswani et al., 2017) •https://papers.nips.cc/paper/7181-attention-is-all-you-need • Attentionという機構のみを用いて自然言語処理を行う Encoder-Decoderモデル 8 Transformerの図 (提案論文より) Encoder Decoder Transformer Block input output
- 9. 関連研究-BERT • 提案論文 • “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” • https://www.aclweb.org/anthology/N19-1423/ • 双方向Transformerを用いた言語モデルと、自然言語処理タ スクにおける事前学習の重要性などを示した • 本論文のモデルのベースとなっている 9
- 10. 事前学習-Masked Language Model • 入力の一部を[MASK]トークンに置き換えて、それを予測する タスク • My dog is hairy. -> My dog is [MASK]. • [MASK]部以外を利用して[MASK]を予想する 10
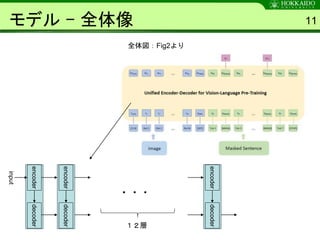
- 11. モデル - 全体像 11 全体図:Fig2より encoderdecoder input encoderdecoder ・・・ 12層 encoderdecoder
- 12. モデル – 入出力 • 入力:画像の領域(N個)、単語(T個)の埋め込みベクトル(d 次元) [CLS], [SEP], [STOP]の特殊トークン3つ • 画像の領域 •𝑅𝑖:i番目の領域の特徴量ベクトル •𝐶𝑖:i番目の領域のクラス分布 •𝐺𝑖:i番目の領域の座標に関するベクトル •𝑊は学習すべき重み • 単語𝑦𝑡 d次元の埋め込みベクトル • 特殊トークン •[CLS]:入力の開始 [SEP]:画像と文を分ける [STOP]: 入力の 終了 12
- 13. モデル – 入出力 • 本当の入力は前ページのものを合わせた 𝐻0 = [𝑟 𝐶𝐿𝑆 , 𝑟1, 𝑟2, … , 𝑟 𝑁, 𝑦 𝑆𝐸𝑃 , 𝑦1, 𝑦2, … , 𝑦 𝑇, 𝑦 𝑆𝑇𝑂𝑃 ] • 以下の式でTransformer Blockを計算 𝐻 𝑙 = 𝑇𝑟𝑎𝑛𝑠𝑓𝑜𝑚𝑒𝑟(𝐻 𝑙−1) • 出力: 𝐻 𝐿 = ℎ 𝑟 𝐶𝐿𝑆 , ℎ 𝑟1 , … , ℎ𝑦 𝑆𝐸𝑃 , ℎ𝑦1, … , ℎ𝑦 𝑇, ℎ𝑦 𝑆𝑇𝑂𝑃 13
- 14. 学習条件の設定 • Bidirectional(双方向) • ある単語のAttentionを計算するときに後ろの単語も 参照できる • Seq2seq • ある単語のAttentionを計算するときに前の単語しか 参照できない ※本モデルでは2つの条件をバッチごとに変えて学習 • 割合をパラメータλで指定 • 事前学習ではλ=0.75で75%がseq2seq 14
- 15. 各タスクの解き方 • 画像キャプション 1. 画像の領域を切り出し、(1)式でベクトル化 2. 画像と[MASK]をモデルに入力し、[MASK]を予測 3. 画像と最初の単語の予測結果、[MASK]をモデルに入 力し、2つ目の[MASK]を予測 4. これを[STOP]が予測されるまで繰り返す ※λ=1.0に設定 15
- 16. 各タスクの解き方 • VQA • 答えの候補となるクラスをあらかじめ定めておき、多 クラス分類として定式化 • [CLS]と[SEP]に対する出力を使い、クラス分類問題 を解く ※λ=0に設定 16
- 17. 実験と結果 – データセット • 事前学習用データセット • Conceptual Captions(CC) •Web上にある画像とキャプションのペア約3百万件 • 画像キャプション用データセット • COCO Captions, Flickr30k • VQA用データセット • VQA 2.0 17
- 18. 実験と結果 - 他のモデルとの比較 • 多くの指標においてSOTAを達成 • 特にFlickr30kではCIDErで5.1pt、BLEU@4で2.8ptの上昇 18 Table2 cross-entropyで最適化した場合の各指標 ※B@4: BLEU@4, M: METEOR, C: CIDEr, S: SPICEを表し、 すべて大きいほど良いスコア
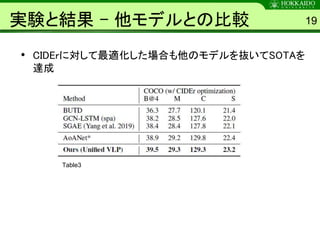
- 19. 実験と結果 – 他モデルとの比較 • CIDErに対して最適化した場合も他のモデルを抜いてSOTAを 達成 19 Table3
- 20. 実験と結果 – 事前学習の効果 • 下流タスクでの性能差から、Unified VLPが他の事前学習モ デルよりも優れたものであることを示した 20 Table4 事前学習手法の違いによる下流タスクの性能差
- 21. 実験と結果 – 事前学習の際の初期化 • 事前学習を行う際の重さの初期値についての実験 • ゼロから事前学習をするよりも、他の言語モデルで初期化を した場合の方が最終的な性能が高くなる傾向がある 21 Table5 事前学習を行う際の初期化
- 22. 実験と結果 - 画像情報の保持に関する実験 • Faster R-CNNの出力 • 領域の特徴量ベクトル、領域のラベル •ラベルを予測するpretext taskを追加する[1] •ラベル分布を入力としてとらえる(本手法) 22 [1] Tan, H., and Bansal, M. 2019. Lxmert: Learning crossmodality encoder representations from transformers. arXiv preprint arXiv:1908.07490.
- 23. 実験と結果 – 出力例と定性的評価 • Unified VLPではumbrellaを認識できている • テキストのみから特徴量を抽出するより、画像との関係性をう まくとらえられているのではないか 23 Figure3から抜粋
- 24. まとめ • Vision-Languageタスクに対してUnified VLPというモデルを提 案 • 単一のTransformerを用いているという点 • 画像キャプション、VQAを同一のモデルで扱える点 • 画像 - テキスト間の特徴量を事前学習で獲得し、モデルの 性能を向上させることに成功した 24