



















































Unsupervised learning and clustering.pdf
- 1. 9.54 Class 13 Unsupervised learning Clustering Shimon Ullman + Tomaso Poggio Danny Harari + Daneil Zysman + Darren Seibert
- 2. Outline • Introduction to clustering • K-means • Bag of words (dictionary learning) • Hierarchical clustering • Competitive learning (SOM)
- 3. What is clustering? • The organization of unlabeled data into similarity groups called clusters. • A cluster is a collection of data items which are “similar” between them, and “dissimilar” to data items in other clusters.
- 4. Historic application of clustering
- 5. Computer vision application: Image segmentation
- 6. What do we need for clustering?
- 7. Distance (dissimilarity) measures They are special cases of Minkowski distance: (p is a positive integer) p p m k jk ik j i p x x d 1 1 ) , ( x x
- 8. Cluster evaluation (a hard problem) • Intra-cluster cohesion (compactness): – Cohesion measures how near the data points in a cluster are to the cluster centroid. – Sum of squared error (SSE) is a commonly used measure. • Inter-cluster separation (isolation): – Separation means that different cluster centroids should be far away from one another. • In most applications, expert judgments are still the key
- 13. K-Means clustering • K-means (MacQueen, 1967) is a partitional clustering algorithm • Let the set of data points D be {x1, x2, …, xn}, where xi = (xi1, xi2, …, xir) is a vector in X Rr, and r is the number of dimensions. • The k-means algorithm partitions the given data into k clusters: – Each cluster has a cluster center, called centroid. – k is specified by the user
- 14. K-means algorithm • Given k, the k-means algorithm works as follows: 1. Choose k (random) data points (seeds) to be the initial centroids, cluster centers 2. Assign each data point to the closest centroid 3. Re-compute the centroids using the current cluster memberships 4. If a convergence criterion is not met, repeat steps 2 and 3
- 15. K-means convergence (stopping) criterion • no (or minimum) re-assignments of data points to different clusters, or • no (or minimum) change of centroids, or • minimum decrease in the sum of squared error (SSE), – Cj is the jth cluster, – mj is the centroid of cluster Cj (the mean vector of all the data points in Cj), – d(x, mj) is the (Eucledian) distance between data point x and centroid mj. k j C j j d SSE 1 2 ) , ( x m x
- 17. K-means clustering example – step 2
- 18. K-means clustering example – step 3
- 22. Why use K-means? • Strengths: – Simple: easy to understand and to implement – Efficient: Time complexity: O(tkn), where n is the number of data points, k is the number of clusters, and t is the number of iterations. – Since both k and t are small. k-means is considered a linear algorithm. • K-means is the most popular clustering algorithm. • Note that: it terminates at a local optimum if SSE is used. The global optimum is hard to find due to complexity.
- 23. Weaknesses of K-means • The algorithm is only applicable if the mean is defined. – For categorical data, k-mode - the centroid is represented by most frequent values. • The user needs to specify k. • The algorithm is sensitive to outliers – Outliers are data points that are very far away from other data points. – Outliers could be errors in the data recording or some special data points with very different values.
- 24. Outliers
- 25. Dealing with outliers • Remove some data points that are much further away from the centroids than other data points – To be safe, we may want to monitor these possible outliers over a few iterations and then decide to remove them. • Perform random sampling: by choosing a small subset of the data points, the chance of selecting an outlier is much smaller – Assign the rest of the data points to the clusters by distance or similarity comparison, or classification
- 26. Sensitivity to initial seeds Random selection of seeds (centroids) Iteration 1 Iteration 2 Random selection of seeds (centroids) Iteration 1 Iteration 2
- 27. Special data structures • The k-means algorithm is not suitable for discovering clusters that are not hyper-ellipsoids (or hyper-spheres).
- 28. K-means summary • Despite weaknesses, k-means is still the most popular algorithm due to its simplicity and efficiency • No clear evidence that any other clustering algorithm performs better in general • Comparing different clustering algorithms is a difficult task. No one knows the correct clusters!
- 29. Application to visual object recognition: Dictionary learning (Bag of Words)
- 30. Learning the visual vocabulary
- 31. Learning the visual vocabulary
- 32. Examples of visual words
- 36. A Dendrogram
- 37. Types of hierarchical clustering • Divisive (top down) clustering Starts with all data points in one cluster, the root, then – Splits the root into a set of child clusters. Each child cluster is recursively divided further – stops when only singleton clusters of individual data points remain, i.e., each cluster with only a single point • Agglomerative (bottom up) clustering The dendrogram is built from the bottom level by – merging the most similar (or nearest) pair of clusters – stopping when all the data points are merged into a single cluster (i.e., the root cluster).
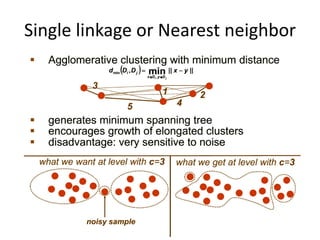
- 40. Single linkage or Nearest neighbor
- 41. Complete linkage or Farthest neighbor
- 43. Object category structure in monkey inferior temporal (IT) cortex
- 44. Kiani et al., 2007 Object category structure in monkey inferior temporal (IT) cortex
- 45. Hierarchical clustering of neuronal response patterns in monkey IT cortex Kiani et al., 2007
- 47. Competitive learning algorithm: Kohonen Self Organization Maps (K-SOM)
- 48. K-SOM example • Four input data points (crosses) in 2D space. • Four output nodes in a discrete 1D output space (mapped to 2D as circles). • Random initial weights start the output nodes at random positions.
- 49. • Randomly pick one input data point for training (cross in circle). • The closest output node is the winning neuron (solid diamond). • This winning neuron is moved towards the input data point, while its two neighbors move also by a smaller increment (arrows). K-SOM example
- 50. • Randomly pick another input data point for training (cross in circle). • The closest output node is the new winning neuron (solid diamond). • This winning neuron is moved towards the input data point, while its single neighboring neuron move also by a smaller increment (arrows). K-SOM example
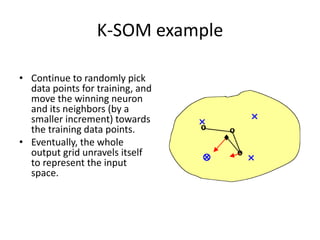
- 51. K-SOM example • Continue to randomly pick data points for training, and move the winning neuron and its neighbors (by a smaller increment) towards the training data points. • Eventually, the whole output grid unravels itself to represent the input space.
- 52. Competitive learning claimed effect
- 53. Hebbian vs. Competitive learning
- 54. Summary • Clustering has a long history and still is in active research – There are a huge number of clustering algorithms, among them: Density based algorithm, Sub-space clustering, Scale-up methods, Neural networks based methods, Fuzzy clustering, Co-clustering … – More are still coming every year • Clustering is hard to evaluate, but very useful in practice • Clustering is highly application dependent (and to some extent subjective) • Competitive learning in neuronal networks performs clustering analysis of the input data