HBaseCon 2015: S2Graph - A Large-scale Graph Database with HBase
46 likes8,858 views

As the operator of the dominant messenger application in South Korea, KakaoTalk has more than 170 million users, and our ever-growing graph has more than 10B edges and 200M vertices. This scale presents several technical challenges for storing and querying the graph data, but we have resolved them by creating a new distributed graph database with HBase. Here you'll learn the methodology and architecture we used to solve the problems, compare it another famous graph database, Titan, and explore the HBase issues we encountered.





















![23
How to read the data - GetEdges
Using a custom query DSL on top of HTTP
curl -XPOST localhost:9000/graphs/getEdges -H 'Content-Type: Application/json' -d '
{
"srcVertices": [{"serviceName": "s2graph", "columnName": "account_id", "id":1}],
"steps": [
[{"label": "friends", "direction": "out", "limit": 100}], // step
[{"label": "hear", "direction": "out", "limit": 10}]
]
}
'
Steps = a list of Step
Step = contains the labels to traverse
and how to rank them in the result
Step 1
friend 1
hear
time: 20140502
hear
time: 20140712
hear
time: 20141116
Friends Friends
friend 2
User 1
Step 2
Don’t let go let it be let it go](https://image.slidesharecdn.com/usecases-session5-150605173423-lva1-app6892/85/HBaseCon-2015-S2Graph-A-Large-scale-Graph-Database-with-HBase-23-320.jpg)
![24
How to read the data - GetEdges Example
Friend list
curl -XPOST localhost:9000/graphs/getEdges -H 'Content-Type: Application/json' -d '
{
"srcVertices": [{"serviceName": "s2graph", "columnName": "account_id", "id":1}],
"steps": [
[{"label": "friends", "direction": "out", "limit": 100}], // step
]
}
'
friend 1 friend 2
User 1
Friends Friends](https://image.slidesharecdn.com/usecases-session5-150605173423-lva1-app6892/85/HBaseCon-2015-S2Graph-A-Large-scale-Graph-Database-with-HBase-24-320.jpg)
![25
How to read the data - GetEdges Example
Songs my friends have listened
curl -XPOST localhost:9000/graphs/getEdges -H 'Content-Type: Application/json' -d '
{
"srcVertices": [{"serviceName": "s2graph", "columnName": "account_id", "id":1}],
"steps": [
[{"label": "friends", "direction": "out", "limit": 50, “scoring”: {“score”: 1.0}],
[{"label": "listen", "direction": "out", "limit": 10}]
]
}
'
friend 1
Friends Friends
friend 2
Don’t let go let it be let it go
hear
time: 20140502
hear
time: 20140712
hear
time: 20141116
User 1
Reference : https://github.com/daumkakao/s2graph#1-definition](https://image.slidesharecdn.com/usecases-session5-150605173423-lva1-app6892/85/HBaseCon-2015-S2Graph-A-Large-scale-Graph-Database-with-HBase-25-320.jpg)
![26
How to read the data - GetEdges Example
Similar songs to songs that I have listened to.
curl -XPOST localhost:9000/graphs/getEdges -H 'Content-Type: Application/json' -d '
{
"srcVertices": [{"serviceName": "s2graph", "columnName": "account_id", "id":1}],
"steps": [
[{"label": "listen", "direction": "out", "limit": 50}],
[{"label": "similar_song", "direction": "out", "limit": 10, “scoring”: {“score”: 1.0}]
]
}
User 1
Don’t let go let it be let it go
hear
time: 20140502
hear
time: 20140712
hear
time: 20141116
let it bleed Hey jude Do you wanna
build a snowman?
similar_song
similarity: 0.3
similar_song
similarity: 0.4
similar_song
similarity: 0.6](https://image.slidesharecdn.com/usecases-session5-150605173423-lva1-app6892/85/HBaseCon-2015-S2Graph-A-Large-scale-Graph-Database-with-HBase-26-320.jpg)
![27
How to read the data - GetVertices
curl -XPOST localhost:9000/graphs/getVertices -H 'Content-Type: Application/json' -d '
[
{"serviceName": "s2graph", "columnName": "account_id", "ids": [1, 2, 3]},
{"serviceName": "kakaomusic", "columnName": "user_id", "ids": [1, 2, 3]}
]
'
User 1
{created_at:20070812,
updated_at:20150507}
User 2
{created_at:201206132,
updated_at:20140505}](https://image.slidesharecdn.com/usecases-session5-150605173423-lva1-app6892/85/HBaseCon-2015-S2Graph-A-Large-scale-Graph-Database-with-HBase-27-320.jpg)
![28
How to write the data - Insert
curl -XPOST localhost:9000/graphs/edges/insert -H 'Content-Type: Application/json' -d '
[
{"from":1,"to":2,"label":"graph_test","props":{"time":-1, "weight":10},"timestamp":1417616431},
]
'
User 1 User 2](https://image.slidesharecdn.com/usecases-session5-150605173423-lva1-app6892/85/HBaseCon-2015-S2Graph-A-Large-scale-Graph-Database-with-HBase-28-320.jpg)
![29
How to write the data - Delete
curl -XPOST localhost:9000/graphs/edges/delete -H 'Content-Type: Application/json' -d '
[
{"from":1,"to":2,"label":"graph_test","timestamp":1417616431},
{"from":1,"to":3,"label":"graph_test","timestamp":1417616431},
]
'
User 1 User 2](https://image.slidesharecdn.com/usecases-session5-150605173423-lva1-app6892/85/HBaseCon-2015-S2Graph-A-Large-scale-Graph-Database-with-HBase-29-320.jpg)
![30
How to write the data - Update
curl -XPOST localhost:9000/graphs/edges/update -H 'Content-Type: Application/json' -d '
[
{"from":1,"to":2,"label":"graph_test","timestamp":1417616431, "props": {"is_hidden": true, “status”: 200},
{"from":1,"to":3,"label":"graph_test","timestamp":1417616431, "props": {"status": -500}
]
User 1 User 2
friend
{is_hidden:true,
status:200}](https://image.slidesharecdn.com/usecases-session5-150605173423-lva1-app6892/85/HBaseCon-2015-S2Graph-A-Large-scale-Graph-Database-with-HBase-30-320.jpg)















































![[263] s2graph large-scale-graph-database-with-hbase-2](https://cdn.slidesharecdn.com/ss_thumbnails/236s2graph-large-scale-graph-database-with-hbase-2-150915055019-lva1-app6892-thumbnail.jpg?width=560&fit=bounds)
Ad
More Related Content
What's hot (20)
Similar to HBaseCon 2015: S2Graph - A Large-scale Graph Database with HBase (20)


















Ad
More from HBaseCon (20)




















Ad
Recently uploaded (20)



![Minitab 22 Full Crack Plus Product Key Free Download [Latest] 2025](https://cdn.slidesharecdn.com/ss_thumbnails/avtpastoralvisits20252026-250407114051-0c8f0fbf-250407123507-bf8f5b04-250426175635-00bc6197-thumbnail.jpg?width=560&fit=bounds)









![Download Wondershare Filmora Crack [2025] With Latest](https://cdn.slidesharecdn.com/ss_thumbnails/neo4j-howkgsareshapingthefutureofgenerativeaiatawssummitlondonapril2024-240426125209-2d9db05d-250419-250428115407-a04afffa-thumbnail.jpg?width=560&fit=bounds)






HBaseCon 2015: S2Graph - A Large-scale Graph Database with HBase
- 1. S2Graph : A large-scale graph database with Hbase daumkakao Doyoung Yoon x Taejin Chin
- 2. 2 DaumKakao A Mobile Lifestyle Platform 1. KakaoTalk a. Mobile Messenger replacing SMS b. ‘KaTalkHe’ is being used as a verb in Korea like ‘Googling’ c. 96% of Korean smartphone users are using KakaoTalk d. 170M users worldwide e. 3B messages / day
- 3. 3 KakaoTalk Social Platform DaumKakao A Mobile Lifestyle Platform KakaoStory KakaoGroup Daum Cafe Contents Platform KakaoTopic KakaoPage KakaoGame Commerce Platform KakaoPick KakaoMusic Marketing Platform Yellow IDMedia Daum Daum tvPot Local Platform Daum Map Daum Webtoon Personal Platform Sol calendarKakaoPlace Sol Mail Zap Plus FriendGift Shop Digital Item Store KakaoStyle KakaoHome Sol Group Story Plus Daum Cluod Biggest mobile SNS in Korea 96% of Korean smartphone users are using KakaoTalk messenger, 170 million users worldwide)
- 4. 4 Our Social Graph Message length : 9 Write length : 3 Read impact :3 Coupon price : 10 Present price : 3 affinity 6affinity: 9 affinity 3 affinity 3 affinity 4 affinity 1 affinity 2 affinity 2 affinity 9 Friend Group size : 6 Emoticon count : 7 Eat rating : 4 View count : 8 Play level: 6 Pick withFriend : 3 Advertise ctr : 0.32 Search keyword : “HBase" Listen count : 6 Like count : 7 Comment length : 15 affinity 3
- 5. 5 Our Social Graph Message length : 9 Write length : 3 affinity 6affinity: 9 affinity 3 affinity 3 affinity 4 affinity 1 affinity 2 affinity 2 affinity 9 Friend Play level: 6 Pick withFriend : 3 Advertise ctr : 0.32 Search keyword : “HBase" Listen count : 6 C l affinity 3 Message ID : 201 Ad ID : 603 Music ID Item ID : 13 Post ID : 97 Game ID : 1984
- 6. 6 Technical Challenges 1. Large social graph constantly changing a. Scale more than, social network: 10 billion edges, 200 million vertices, 50 million update on existing edges. user activities: 400 million new edges per day
- 7. 7 Technical Challenges (cont) 2. Low latency for breadth first search traversal on connected data. a. performance requirement peak graph-traversing query per second: 20000 response time: 100ms
- 8. 8 Technical Challenges (cont) 3. Update should be applied to graph in real time for viral effect Person A Post Fast Person B Comment Person C Sharing Person D Mention Fast Fast
- 9. 9 Technical Challenges (cont) 4. Support for Dynamic Ranking logic a. push strategy: hard to change data ranking logic dynamically. b. pull strategy: can try various data ranking logic
- 10. 10 Before Each app server should know each DB’s sharding logic. Highly inter-connected architecture Friend relationship SNS feeds Blog user activities Messaging Messaging App SNS App Blog App
- 12. 12 S2Graph : Distributed Online GraphDB 1. Low-latency 2.Graph-traversable 3.Scalable 4.Eventually consistent 5.Asynchronous, non-blocking
- 13. 13 Why We Choose HBase? 1. High Availability 2.Scalability 3.Low latency 4.High concurrency 5.Fault tolerant 6.Integration with HDFS 7.Distributed operation
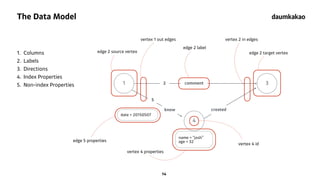
- 14. 14 The Data Model 1. Columns 2. Labels 3. Directions 4. Index Properties 5. Non-index Properties 1 3comment 4 know created name = “josh” age = 32 edge 2 source vertex vertex 1 out edges edge 2 target vertex 2 edge 2 label vertex 2 in edges vertex 4 id vertex 4 properties date = 20150507 edge 5 properties 5
- 15. 15 How to store the data - Edge Logical View 1. Snapshot edges : Up-to-date status of edge column row Tgt Vertex ID1 Tgt Vertex ID2 Tgt Vertex ID3 Src Vertex ID1 Properties Properties Properties Src Vertex ID2 Properties Properties Properties a. Fetching an edge between two specific vertex b. Lookup Table to reach indexed edges for update, increment, delete operations
- 16. 16 How to store the data - Edge Logical View 2. Indexed edges : Edges with index column row Index Values | Tgt Vertex ID1 Index Values | Tgt Vertex ID2 Src Vertex ID1 Non-index Properties Non-index Properties a. Fetches edges originating from a certain vertex in order of index
- 17. 17 How to store the data - Edge Physical View - table schema 1. Snapshot Edge a. Rowkey Murmur Hash Src Vertex ID Label ID Direction Index Sequence Is Inverted 16 bit variable length 30 bit 2 bit 7bit 1 bit Vertex IDs can be encoded with 8 bit header + byte array (long, integer, short, byte, string)
- 18. 18 How to store the data - Edge Physical View - table schema 1. Snapshot Edge b. Qualifier Target Vertex ID variable length c. Value All Property Key Value Pairs variable length
- 19. 19 How to store the data - Edge Physical View - table schema 2. Indexed Edge a. Rowkey Murmur Hash Src Vertex ID Label ID Direction Index Sequence Is Inverted 16 bit variable length 30 bit 2 bit 7bit 1 bit Vertex IDs can be encoded with 8 bit header + byte array (long, integer, short, byte, string)
- 20. 20 How to store the data - Edge Physical View - table schema 2. Indexed Edge b. Qualifier Index Property Values Tgt Vertex ID variable length variable length c. Value Non-index Property Key Value Pairs variable length
- 21. 21 How to store the data - Vertex Logical View 1. Vertex : Up-to-date status of Vertex column row Property Key1 Property Key2 Src Vertex ID1 Value1 Value2 Vertex ID2 Value1 Value2
- 22. 22 How to store the data - Vertex Physical View - table schema 1. Vertex : Up-to-date status of Vertex a. Rowkey Murmur Hash Column ID Vertex ID 16 bit integer(32bit) variable length b. Qualifier Property Key Byte(8 bit) c. Value Property Value variable length
- 23. 23 How to read the data - GetEdges Using a custom query DSL on top of HTTP curl -XPOST localhost:9000/graphs/getEdges -H 'Content-Type: Application/json' -d ' { "srcVertices": [{"serviceName": "s2graph", "columnName": "account_id", "id":1}], "steps": [ [{"label": "friends", "direction": "out", "limit": 100}], // step [{"label": "hear", "direction": "out", "limit": 10}] ] } ' Steps = a list of Step Step = contains the labels to traverse and how to rank them in the result Step 1 friend 1 hear time: 20140502 hear time: 20140712 hear time: 20141116 Friends Friends friend 2 User 1 Step 2 Don’t let go let it be let it go
- 24. 24 How to read the data - GetEdges Example Friend list curl -XPOST localhost:9000/graphs/getEdges -H 'Content-Type: Application/json' -d ' { "srcVertices": [{"serviceName": "s2graph", "columnName": "account_id", "id":1}], "steps": [ [{"label": "friends", "direction": "out", "limit": 100}], // step ] } ' friend 1 friend 2 User 1 Friends Friends
- 25. 25 How to read the data - GetEdges Example Songs my friends have listened curl -XPOST localhost:9000/graphs/getEdges -H 'Content-Type: Application/json' -d ' { "srcVertices": [{"serviceName": "s2graph", "columnName": "account_id", "id":1}], "steps": [ [{"label": "friends", "direction": "out", "limit": 50, “scoring”: {“score”: 1.0}], [{"label": "listen", "direction": "out", "limit": 10}] ] } ' friend 1 Friends Friends friend 2 Don’t let go let it be let it go hear time: 20140502 hear time: 20140712 hear time: 20141116 User 1 Reference : https://github.com/daumkakao/s2graph#1-definition
- 26. 26 How to read the data - GetEdges Example Similar songs to songs that I have listened to. curl -XPOST localhost:9000/graphs/getEdges -H 'Content-Type: Application/json' -d ' { "srcVertices": [{"serviceName": "s2graph", "columnName": "account_id", "id":1}], "steps": [ [{"label": "listen", "direction": "out", "limit": 50}], [{"label": "similar_song", "direction": "out", "limit": 10, “scoring”: {“score”: 1.0}] ] } User 1 Don’t let go let it be let it go hear time: 20140502 hear time: 20140712 hear time: 20141116 let it bleed Hey jude Do you wanna build a snowman? similar_song similarity: 0.3 similar_song similarity: 0.4 similar_song similarity: 0.6
- 27. 27 How to read the data - GetVertices curl -XPOST localhost:9000/graphs/getVertices -H 'Content-Type: Application/json' -d ' [ {"serviceName": "s2graph", "columnName": "account_id", "ids": [1, 2, 3]}, {"serviceName": "kakaomusic", "columnName": "user_id", "ids": [1, 2, 3]} ] ' User 1 {created_at:20070812, updated_at:20150507} User 2 {created_at:201206132, updated_at:20140505}
- 28. 28 How to write the data - Insert curl -XPOST localhost:9000/graphs/edges/insert -H 'Content-Type: Application/json' -d ' [ {"from":1,"to":2,"label":"graph_test","props":{"time":-1, "weight":10},"timestamp":1417616431}, ] ' User 1 User 2
- 29. 29 How to write the data - Delete curl -XPOST localhost:9000/graphs/edges/delete -H 'Content-Type: Application/json' -d ' [ {"from":1,"to":2,"label":"graph_test","timestamp":1417616431}, {"from":1,"to":3,"label":"graph_test","timestamp":1417616431}, ] ' User 1 User 2
- 30. 30 How to write the data - Update curl -XPOST localhost:9000/graphs/edges/update -H 'Content-Type: Application/json' -d ' [ {"from":1,"to":2,"label":"graph_test","timestamp":1417616431, "props": {"is_hidden": true, “status”: 200}, {"from":1,"to":3,"label":"graph_test","timestamp":1417616431, "props": {"status": -500} ] User 1 User 2 friend {is_hidden:true, status:200}
- 31. 31 REST API Spec. Read 1. getEdges 2. checkEdge 3. getEdgesCount 4. getVertices Write 1. insert 2. delete 3. update 4. increment Management 1. create service (vertex type) 2. create label (edge type) 3. add Index
- 32. 32 HBase Table Configuration 1. setDurability(Durability.ASYNC_WAL) 2. setCompressionType(Compression.Algorithm.LZ4) 3. setBloomFilterType(BloomType.Row) 4. setDataBlockEncoding(DataBlockEncoding.FAST_DIFF) 5. setBlockSize(32768) 6. setBlockCacheEnabled(true) 7. pre-split by (Intger.MaxValue / regionCount). regionCount = 120 when create table(on 20 region server).
- 33. 33 HBase Cluster Configuration • each machine: 8core, 32G memory • hfile.block.cache.size: 0.6 • hbase.hregion.memstore.flush.size: 128MB • otherwise use default value from CDH 5.3.1
- 35. 35 Compare to other Online GraphDBs Titan (v0.4.2) a. Pros - Rich API and easy to setup - Relatively large community - Transaction handling b. Cons - Using it’s own ID system; less efficient for graph traversal (details in next slide) - Index data stored on one region (hotspot) with strong consistency option - Not many references on Titan with HBase comparing to other storages
- 36. 36 Compare to Titan Titan is less efficient for graph traversal - For following 1 normal graph traversal query, Vertex(“userID:1”).out(“friends”).limit(10).out(“friends”).limit(10) User 1 friends friends
- 37. 37 Compare to Titan (cont) Vertex(“userID:1”).out(“friend”).limit(10).out(“friend”).limit(10) Titan S2graph # of read requests on HBase 112 = 1 (Vertex Lookup : a) + 1 (1st step edges : b) + 10 (2nd step edges : c) + 100 (Destination Vertices : d) 11 = 1 (1step edges : e) + 10 (2nd step edges : f) Titan S2graph B A C D e f
- 38. 38 Performance 1. Test data a. Total # of Edges: 9,000,000,000 b. Average # of adjacent edges per vertex: 500 c. Seed vertex: vertices that has more than 100 adjacent edges. 2. Test environment a. Zookeeper server: 3 b. HBase Masterserver: 2 c. HBase Regionserver: 20 d. App server: 8 core, 16GB Ram
- 39. 39 - Benchmark Query : src.out(“friend”).limit(50).out(“friend”).limit(10) - Total concurrency: 20 * # of app server Performance 2. Linear scalability Latency 0 50 100 150 200 QPS 0 1,000 2,000 3,000 4,000 # of app server 1 2 4 8 QPS(Query Per Second) Latency(ms) 51515047 3,097 1,567 803 42147 50 51 51 # of app server 1 2 3 4 5 6 7 8 50010001500200025003000 QPS
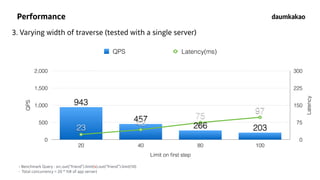
- 40. 40 Performance 3. Varying width of traverse (tested with a single server) Latency 0 75 150 225 300 QPS 0 500 1,000 1,500 2,000 Limit on first step 20 40 80 100 QPS Latency(ms) 97 75 43 23 203266 457 943 23 43 75 97 - Benchmark Query : src.out(“friend”).limit(x).out(“friend”).limit(10) - Total concurrency = 20 * 1(# of app server)
- 41. Performance 3. Varying width of traverse (tested with a single server) Latency 0 75 150 225 300 QPS 0 500 1,000 1,500 2,000 Limit on first step 20 40 80 100 QPS Latency(ms) 97 75 43 23 203266 457 943 23 43 75 97 - Benchmark Query : src.out(“friend”).limit(x).out(“friend”).limit(10) - Total concurrency = 20 * 1(# of app server)
- 42. 42 - All query touch 1000 edges. - each step` limit is on x axis. - Can expect performance with given query`s search space. Performance 4. Different query path(different I/O pattern) Latency 0 37.5 75 112.5 150 QPS 0 80 160 240 320 400 limits on path 10 -> 100 100 -> 10 10 -> 10 -> 10 2 -> 5 -> 10 -> 10 2 -> 5 -> 2 -> 5 -> 10 QPS Latency(ms) 5667716867 352.2 298.1280272.5297 67 68 71 67 56
- 43. 43 Performance 5. Write throughput per operation on single app server Insert operation Latency 0 1.25 2.5 3.75 5 Request per second 8000 16000 800000
- 44. 44 Performance 6. write throughput per operation on single app server Update(increment/update/delete) operation Latency 0 2 4 6 8 Request per second 2000 4000 6000
- 45. 45 Stats 1. HBase cluster per IDC (2 IDC) - 3 Zookeeper Server - 2 HBase Master - 20 HBase Slave 2. App server per IDC - 10 server for write-only - 20 server for query only 3. Real traffic - read: over 10K request per second - now mostly 2 step queries with limit 100 on first step. - write: over 5k request per second * Deep traversal queries are not counted since it is in test stage for production
- 46. 46
- 48. 48 Now Available As an Open Source - https://github.com/daumkakao/s2graph - Finding a mentor Contact - Taejin Chin : [email protected] - Doyoung Yoon : [email protected]
- 49. 49 Latency 0 50 100 150 200 QPS 0 500 1,000 1,500 2,000 # of app server 1 2 3 4 5 Native Client QPS Native Client Latency(ms) 174186189 177178 570 429315224112 178 177 189 186 174 - Benchmark Query : src.out(“friend”).limit(50).out(“friend”).limit(10) - Test seed edges have adjacent edges more than 100: 30millions - Total concurrency: 20 * # of app server Appendix Latency 0 50 100 150 200 QPS 0 500 1,000 1,500 2,000 # of app server 1 2 3 4 5 Asnychbase QPS Asynchbase Latency(ms) 5351505047 1,895 1,567 1,192 803 421 47 50 50 51 53 3.5x performance improvement using Asynchbase