Using Graph and Transformer Embeddings for Vector Based Retrieval

For the longest time, term-based vector representations based on whole-document statistics, such as TF-IDF, have been the staple of efficient and effective information retrieval. The popularity of Deep Learning over the past decade has resulted in the development of many interesting embedding schemes. Like term-based vector representations, these embeddings depend on structure implicit in language and user behavior. Unlike them, they leverage the distributional hypothesis, which states that the meaning of a word is determined by the context in which it appears. These embeddings have been found to better encode the semantics of the word, compared to term-based representations. Despite this, it has only recently become practical to use embeddings in Information Retrieval at scale. In this presentation, we will describe how we applied two new embedding schemes to Scopus, Elsevier’s broad coverage database of scientific, technical, and medical literature. Both schemes are based on the distributional hypothesis but come from very different backgrounds. The first embedding is a graph embedding called node2vec, that encodes papers using citation relationships between them as specified by their authors. The second embedding leverages Transformers, a recent innovation in the area of Deep Learning, that are essentially language models trained on large bodies of text. These two embeddings exploit the signal implicit in these data sources and produce semantically rich user and content-based vector representations respectively. We will evaluate these embedding schemes and describe how we used the Vespa search engine to search these embeddings for similar documents within the Scopus dataset. Finally, we will describe how RELX staff can access these embeddings for their own data science needs, independent of the search application.







































![[SUB] Deep learning model to 2Bit Quantization?! BRECQ Paper review (2021 ICLR)](https://cdn.slidesharecdn.com/ss_thumbnails/brecqpresent-210309082349-thumbnail.jpg?width=560&fit=bounds)


























More Related Content
What's hot (20)
Similar to Using Graph and Transformer Embeddings for Vector Based Retrieval (20)


















More from Sujit Pal (20)




















Recently uploaded (20)




















Using Graph and Transformer Embeddings for Vector Based Retrieval
- 1. Using Graph and Transformer Embeddings for Vector based retrieval Sujit Pal Tony Scerri 4 November 2020
- 2. Agenda • Term vs Vector vs Graph Search • Problem Formulation • Experiments and Results • Conclusions and Future Work 2
- 3. Term vs Vector vs Graph Search 3
- 5. Intuition 5 Query: Donald Trump Term based: Donald Trump Donald Trump, Jr.
- 6. Intuition 6 Query: Donald Trump Term based: Donald Trump Donald Trump, Jr. Vector based: Melania Trump Ivanka Trump Jared Kushner Barack Obama George W Bush Hillary Clinton Joe Biden
- 7. Intuition 7 Query: Donald Trump Term based: Donald Trump Donald Trump, Jr. Vector based: Melania Trump Ivanka Trump Jared Kushner Barack Obama George W Bush Hillary Clinton Joe Biden Graph based: Rudy Giuliani Bill Barr Paul Manafort Michael Flynn Michael Cohen Jeffrey Epstein Prince Andrew Robert Mueller III Christopher Steele
- 8. Term based search • Query and documents represented as high dimensional sparse vectors of term weights. • Inverted index works well with sparse vectors. • Term based search captures term similarity / overlap. • Unsupervised operation. • Scales to large document sets. • BM25 more popular nowadays for ranking. 8
- 9. Vector based search • Based on Distributional Hypothesis. • Leverages “word” and other embeddings. • Can be based on document content or document graph structure. • Captures semantic similarity • Vectors are low dimensional and dense. • Approximate Nearest Neighbor (ANN) methods work best. 9
- 10. Graph based search and reranking 10 • Leverages relationships between documents. • Citation graph, co-authorship network, term/concept co-occurrence networks, etc. • We use the SCOPUS citation graph to calculate: • Citation Count • PageRank • Localized citation count (based on results set) • Combinations based on relative ranks or normalized scores • Re-rank using computed graph metrics.
- 11. Graph based search examples • Global graph metrics (e.g. PageRank) • Indicates importance. 11 • Graph neighborhood features (e.g. Node2Vec) • Indicates Topological similarity
- 12. Graph + Vector Hybrid search • SPECTER: Document level learning using citation-informed Transformers • Minimize Triplet loss between papers • Related/Unrelated papers based on citation graph 12
- 13. Evaluation Metric: NDCG • Search Result Quality measured with Normalized Discounted Cumulative Gain (NDCG). • Measured for k=1, 3, 5, 10, 20, 50. • rel(i) is relevance score, usually relevance(query, document(i)). 13
- 15. Reformulating the Problem • Objective – quantitatively compare various search approaches on SCOPUS. • Needed labeled data, i.e., judgement lists, which weren't available. • TREC-COVID has (incomplete) judgement lists (35 queries so far) • TREC-COVID uses CORD-19 data (from 01-May-2020), some of which are available in SCOPUS. • Some degree of duplication within corpus causes minor discrepancies • Using subset of SCOPUS papers from May 1 CORD-19 dataset. • Using subset of TREC-COVID judgement lists for these papers. • Promising candidate solutions applied back to SCOPUS. 15
- 16. Setup • SOLR index created from CORD-19 corpus (Scopus subset only) • Original plus stemmed fields • Baseline created using eDismax query applied to original and stemmed fields • NDCG measured with filtered (to Scopus) judgements • Various reranking schemes applied to eDismax results • Alternative query methods (SOLR MLT, vector based query) tried 16
- 18. Conditions • Unless otherwise stated: • Use of query from CORD-19 (not question or narrative descriptions) • NDCG based on Scopus matched records only • NDCG reported is the average across all 35 queries 18
- 19. Basic Search • eDismax (original text and stemmed) • MLT (using top edismax result) • Using title, abstract and body fields (where available) • Experiment removing coronavirus or using only coronavirus for each query 19 Full NDCG is based on the full set of matching documents NDCG @1 @3 @5 @10 @20 @50 Full eDismax (orig) 0.41428 0.33743 0.33996 0.32035 0.29261 0.26126 0.54092 eDisMax (stem) 0.44285 0.37126 0.35589 0.32939 0.29697 0.26580 0.54744 MLT (stem) 0.41428 0.29457 0.26813 0.23619 0.19322 0.15559 0.38331 Just "coronavirus" 0 0 0.00604 0.00701 0.00608 0.01003 0.29161 Without "coronavirus" 0.27142 0.22841 0.23478 0.22058 0.21453 0.19836 0.46307
- 21. Reranking • As previously mentioned, various reranking schemes were tried - • Cited By (descending) • PageRank (descending) • Localized Cited By (descending) • Combination included - • Relevancy + PageRank (ranks, ascending) • Relevancy * PageRank (normalized inverse ranks, ascending) • Cited By + Localized Cited By (ranks, ascending) • Relevancy + Cited By (ranks, ascending) • Relevancy + Localized Cited By (ranks, ascending) • Relevancy + (10%) Localized Cited By (normalized scores, descending) • Relevancy + (10%) PageRank (normalized scores, descending) 21
- 22. Reranking Results 22 NDCG @1 @3 @5 @10 @20 @50 Full Cited By 0 0 0 0 0.00104 0.00123 0.28192 PageRank 0 0 0 0.00515 0.00343 0.00484 0.28854 Localized CB 0 0.00335 0.01319 0.008832 0.02060 0.01347 0.31731 Rel+PR Ranks 0.11428 0.08731 0.07885 0.06334 0.05242 0.04228 0.34680 Rel*PR Ranks 0.11428 0.08731 0.07885 0.06334 0.05242 0.04208 0.34007 CB+LCB Ranks 0 0 0.00187 0.00436 0.00541 0.00762 0.30514 Rel+CB Ranks 0.07142 0.06121 0.05258 0.04764 0.03682 0.03160 0.33967 Rel+LCB Ranks 0.08571 0.07725 0.08522 0.07550 0.06465 0.06281 0.38644 Rel+0.1LCB Score 0.44285 0.37039 0.35858 0.33305 0.29205 0.26444 0.54096 Rel+0.1PR Score 0.41428 0.35626 0.34943 0.32226 0.28849 0.25534 0.53191 eDisMax (stem) 0.44285 0.37126 0.35589 0.32939 0.29697 0.26580 0.54744 The full results list from the stemmed eDismax query were used to rerank Most significantly lower than pure eDisMax
- 24. (Searching) Ranking • Sorting of the full corpus, no cut-off applied • Vector based reranking including: • BERT embedding • Node2Vec embeddings • SPECTER embeddings • Compare BERT embedding vector distance of query to title and abstract • Cosine distance and Euclidean distance • Query vs • Title • Title + Abstract (max or mean pooling) • Also tried best eDismax result document per query 24
- 25. Extra Embedding • Also looked at the question and narrative compared to the query, eg • Query : coronavirus origin • Question : what is the origin of COVID-19 • Narrative : seeking range of information about the SARS-CoV-2 virus's origin, including its evolution, animal source, and first transmission into humans • Question and narratives work better • Likely due to longer text with words (including synonyms and concepts) in context (more natural) 25
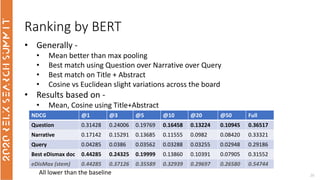
- 26. Ranking by BERT 26 NDCG @1 @3 @5 @10 @20 @50 Full Question 0.31428 0.24006 0.19769 0.16458 0.13224 0.10945 0.36517 Narrative 0.17142 0.15291 0.13685 0.11555 0.0982 0.08420 0.33321 Query 0.04285 0.0386 0.03562 0.03288 0.03255 0.02948 0.29186 Best eDismax doc 0.44285 0.24325 0.19999 0.13860 0.10391 0.07905 0.31552 eDisMax (stem) 0.44285 0.37126 0.35589 0.32939 0.29697 0.26580 0.54744 • Generally - • Mean better than max pooling • Best match using Question over Narrative over Query • Best match on Title + Abstract • Cosine vs Euclidean slight variations across the board • Results based on - • Mean, Cosine using Title+Abstract All lower than the baseline
- 27. Ranking by BERT (cont’d) 27
- 28. Ranking by Node2Vec • Node embedding for node2vec as the query • Results – Cosine, single top result from eDismax with stemming as the query • Some query top results were not in the edge list and therefor yield zero NDCG • Core network, all edges connect two CORD documents • Extended network, all edges touch one CORD document 28 NDCG @1 @3 @5 @10 @20 @50 Full Core 0.44285 0.21205 0.15721 0.10224 0.06997 0.04739 0.33174 Extended 0.44285 0.21628 0.16048 0.10527 0.06909 0.04360 0.32761 eDisMax (stem) 0.44285 0.37126 0.35589 0.32939 0.29697 0.26580 0.54744
- 29. Ranking by Node2Vec (cont’d) 29
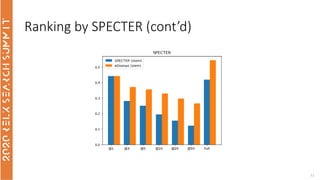
- 30. Ranking by SPECTER • SPECTER document embedding for the query • as calculated by the CORD-19 • Best document returned by eDismax queries 30 NDCG @1 @3 @5 @10 @20 @50 Full Stemmed 0.44285 0.28204 0.25158 0.19540 0.15484 0.12281 0.41963 eDisMax (stem) 0.44285 0.37126 0.35589 0.32939 0.29697 0.26580 0.54744
- 31. Ranking by SPECTER (cont’d) 31
- 32. Training Embedding • Short experiment to look at training query – document for improved ranking • We did not try this with question or narrative, limiting to query • Poor results assumed to be caused by: • Lack of variability in query preventing generalisation • Nearly all queries contain "coronavirus" 32
- 33. Final Results • Taking the best results from each set of experiments • None of the reranking strategies, including the embedding based ones (content, graph, or hybrid) beat the stemmed eDismax baseline. 33 NDCG @1 @3 @5 @10 @20 @50 Full Rel + 0.1*LCB 0.44285 0.37039 0.35858 0.3305 0.29205 0.26444 0.54096 BERT reranking 0.44285 0.24325 0.19999 0.13860 0.10391 0.07905 0.31552 Node2Vec core 0.44285 0.21205 0.15721 0.10224 0.06997 0.04739 0.33174 SPECTER (stem) 0.44285 0.28204 0.25158 0.19540 0.15484 0.12281 0.41963 eDisMax (stem) 0.44285 0.37126 0.35589 0.32939 0.29697 0.26580 0.54744
- 35. Conclusions and Future Work 35
- 36. Summary • CORD-19 corpus with incomplete judgement data (they are continuing to add to it based on results from systems) • eDismax appear to do ok... • Recall suffers due to term mismatching • Beyond basic synonym • Query intent is represented by a single limiting query clause • The question and narrative descriptors provide much more natural text for embeddings to work from • Graph metrics for importance may have limited application depending on user task • Incomplete judgement data make NDCG questionable • ...insufficient information on sampling to apply infNDCG • Question over embedding general sense of semantic equivalence vs concept identity (synonyms) 36
- 37. Future Work • Experiments based on Scopus and our own judgement data • Application of graph metrics, including more than just basic citation graph • Investigation of fine-tuned embeddings combining text and graph • Apply ML based reranking • Investigate the balance between concept, semantic, freshness and importance 37
- 38. Questions? 38