Using Spark and Riak for IoT Apps—Patterns and Anti-Patterns: Spark Summit East talk Pavel Hardak
10 likes2,037 views

The document discusses IoT application development using Spark and Riak, emphasizing the rapid growth of connected devices and the importance of various IoT protocols and data management strategies. It highlights the challenges of data handling, including velocity, variety, volume, and veracity, while advocating for effective data retention policies and the use of specialized databases for time series data. Additionally, it outlines an architectural framework for IoT data processing and examines the advantages of open-source technologies in creating scalable IoT applications.








































![Thank You!
Contact me at [pavel at basho dot com]](https://image.slidesharecdn.com/8apavelhardak-170215221111/85/Using-Spark-and-Riak-for-IoT-Apps-Patterns-and-Anti-Patterns-Spark-Summit-East-talk-Pavel-Hardak-46-320.jpg)

Using Spark and Riak for IoT Apps—Patterns and Anti-Patterns: Spark Summit East talk Pavel Hardak
- 1. Using Spark and Riak for IoT apps Patterns and Anti-patterns Pavel Hardak Basho Technologies
- 2. IOT & INDUSTRY VERTICALS
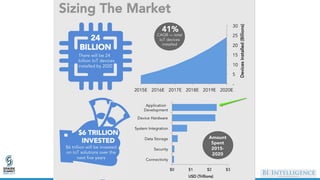
- 3. IoT market - growth prediction Number of connected “things” •2016 – about 6.4 B •30% YoY growth, 5.5M activations per day •2020 – about 21 B “By 2020 more than half of new major business processes and systems will incorporate some element of Internet of Things”
- 5. Copyright © 2017 Daniel Elizalde We want to be here!
- 6. IoT Project Plan •Investigate those “things” and figure out • What protocols they support (CoAP, MQTT, HTTP, …) • What data they generate (temperature, humidity, location, speed, ...) •Collect this data in our data center • Implement protocols and parsing routines • Store into persistent storage (“Data Lake” architecture) •Once stored in Data Lake • Analyze, summarize, “slice and dice” • Predict, make recommendations, discover insights •Declare a victory (make profit, go for IPO, …)
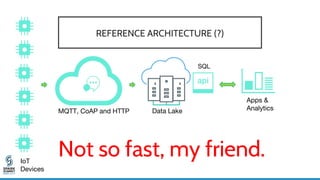
- 7. Data Lake IoT Devices SQL Apps & AnalyticsMQTT, CoAP and HTTP REFERENCE ARCHITECTURE (?) Not so fast, my friend.
- 8. What is wrong with “Data Lake” for IoT ?
- 13. What is different special about IoT? It is about the “things”… and more.
- 16. IoT Networks and Protocols
- 17. IoT Devices & IoT Network Protocols •Wireless technologies •Limited range •Limited bandwidth •Shared transmission media •Mesh or Ad-hoc Topology •Possible signals interference •Low cost hardware components •Low power radio transmitters •Very small antennas •“Custom-made” firmware •Constrained Application Protocol (CoAP) •“Best Effort” QoS (“shoot and forget”)
- 18. IoT is “Big Data” - by definition. Actually, lots and lots of Big Data.
- 19. IoT Data Categories Category Description Metadata & Profiles Devices Device info (model, SN, firmware, sensors, ..), configuration, owner, … Users Personal info, preferences, billing info, registered devices, … Time Series Ingested (“Raw”) Measurements, statuses and events from devices. Aggregated (“Derived”) Calculated data - from devices & profiles • Rollups – aggregate metrics from low resolution to higher ones (min - hour – day) using min, max, avg, ... • Aggregations – aggregate measurements, configuration and profiles (model, region, …) over time ranges
- 20. Five “V”s IoT data Velocity Torrent of small writes (sensors). Reads – millions of low-latency queries: user and device profiles, range queries for TS data (slices). Stream of updates (profiles) - beware of conflicts.
- 21. Five “V”s IoT data Velocity Torrent of small writes (sensors). Reads – millions of low-latency queries, user and device profiles, range queries for TS data (slices). Stream of updates (profiles) - beware of conflicts. Variety Sensors data (time series), users and devices profiles, also time series “derived” data (e.g. rollups, aggregations).
- 22. Five “V”s IoT data Velocity Torrent of small writes (sensors). Reads – millions of low-latency queries, user and device profiles, range queries for TS data (slices). Stream of updates (profiles) - beware of conflicts. Variety Sensors data (time series), users and devices profiles, also time series “derived” data (e.g. rollups, aggregations). Volume Starts small, grows quickly, keeps coming 24x7x365 (nights, weekends and holidays). Spikes up on new model launches or successful marketing campaign. Can slow down, but will keep growing. Efficient data retention policy is critical to prevent overflows.
- 23. Five “V”s IoT data Velocity Torrent of small writes (sensors). Reads – millions of low-latency queries, user and device profiles, range queries for TS data (slices). Stream of updates (profiles) - beware of conflicts. Variety Sensors data (time series), users and devices profiles, also time series “derived” data (e.g. rollups, aggregations). Volume Starts small, grows quickly, keeps coming 24x7x365 (nights, weekends and holidays). Spikes up on new model launches or successful marketing campaign. Can slow down, but will keep growing. Efficient data retention policy is critical to prevent overflows. Veracity Generally trustworthy, but beware of “low cost” sensors with low accuracy. Sent over not-so-reliable transport - expect that some data will be corrupted or arrive late or might be lost. (Hopefully the devices were not hijacked or impersonated by hackers)
- 24. Five “V”s IoT data Velocity Torrent of small writes (sensors). Reads – millions of low-latency queries, user and device profiles, range queries for TS data (slices). Stream of updates (profiles) - beware of conflicts. Variety Sensors data (time series), users and devices profiles, also time series “derived” data (e.g. rollups, aggregations). Volume Starts small, grows quickly, keeps coming 24x7x365 (nights, weekends and holidays). Spikes up on new model launches or successful marketing campaign. Can slow down, but will keep growing. Efficient data retention policy is critical to prevent overflows. Veracity Generally trustworthy, but beware of “low cost” sensors with low accuracy. Sent over not-so-reliable transport - expect that some data will be corrupted or arrive late or might be lost. (Hopefully the devices were not hijacked or impersonated by hackers) Value Profiles and summaries are much more valuable than raw data samples. The value of “raw” time series quickly goes down after it was processed and clock advanced. Aggregated (”derived”) data are more valuable than raw data. Exceptions: financial transactions, life support, nuclear plants, oil rigs, …
- 25. Five “V”s IoT data Velocity Torrent of small writes (sensors). Reads – millions of low-latency queries, user and device profiles, range queries for TS data (slices). Stream of updates (profiles) - beware of conflicts. Variety Sensors data (time series), users and devices profiles, also time series “derived” data (e.g. rollups, aggregations). Volume Starts small, grows quickly, keeps coming 24x7x365 (nights, weekends and holidays). Spikes up on new model launches or successful marketing campaign. Can slow down, but will keep growing. Efficient data retention policy is critical to prevent overflows. Veracity Generally trustworthy, but beware of “low cost” sensors with low accuracy. Sent over not-so-reliable transport - expect that some data will be corrupted or arrive late or might be lost. (Hopefully the devices were not hijacked or impersonated by hackers) Value Profiles and summaries are much more valuable than raw data samples. The value of “raw” time series quickly goes down after it was processed and clock advanced. Aggregated (”derived”) data are more valuable than raw data. Exceptions: financial transactions, life support, nuclear plants, oil rigs, … Complexity Poly-structured using simple schemas and simple relations (usually implicit). Some data is treated as unstructured (”opaque”) for speed or flexibility. Note: expect schema or structure changes without preliminary notice.
- 27. How are we going to solve it ?
- 28. IoT Data & Processing • Data • Huge amounts of data records - arriving 24x7x365 • Some data records will arrive out-of-order, be late (minutes or hours) or lost • Expect “unexpected” - e.g. errors, nulls, schema or type changes, drops • Processing • Preprocessing - validation and cleansing • Translation (format, type, version, ...) and enrichment • Aggregations - min, max, avg, sum, top or bottom N, percentile, … • Grouping - device vendor and model, location, service, subscription type, ... • Rollups - from 10 sec raw samples to 1 min, 1 hour, 1 day, 1 week, 1 month, .. • Alarms (e.g. threshold crossing), anomaly detection (using ML) • Predefined reports (e.g. daily, weekly, …) • Ad-hoc reports or exploratory queries • Insights, predictions, …
- 29. Architectural Blueprints •Lambda Architecture by Nathan Marz (ex-Twitter) •Kappa Architecture by Jay Kreps (Confluent) •Zeta Architecture by Jim Scott (MapR) •… and their variants Lambda Kappa Zeta
- 30. Data Processing Framework for IoT • Uses “Best of breed” OSS technologies • Combines two paradigms • “Speed Layer” – pipeline for Stream Processing for “Data in Motion” • “Serving Layer” – analytics for “Data in Motion” and “Data at Rest” • Every component is “Distributed by Design” • Collection Layer • Message Queue • Stream Processing • Data Storage (Database, Object System, Data Warehouse) • Query and Analytics Engines
- 31. Data store for IoT – “Wish list” • Ingested (Raw) Time Series • Very high write throughput • Fast slice (time range) reads • Aggregated (Derived) Time Series • Auto-distributed + slice locality • SQL-like queries • Aggregations • Bulk queries (analytics) • Secondary Indexes (Tags) • Efficient Storage • Auto Data Retention (TTL) • Build-in anti entropy • Compression • Hot Backups • Profiles and Metadata • Many concurrent reads with low latency • Reliable writes (ACID or conflict resolution) • Unstructured or partially structured • Secondary Indexes + Text Search • Scalability and Availability • Distributed architecture, no SPoF • Linearly scalable - up and down • Operational simplicity • Masterless architecture • Automatic rebalancing • Metrics, logs, events • Rolling upgrades
- 32. What DB type is a good fit for TS use cases?
- 33. Data Access Patterns Category Description R:W % Metadata & Profiles Devices & Users Many low latency small reads - all over the dataset. Occasional updates – possibly by different “actors” (web, device, app), conflicts need to be prevented or resolved. Fewer creates and deletes. 90:10 Time Series
- 34. Data Access Patterns Category Description R:W % Metadata & Profiles Devices & Users Many low latency small reads - all over the dataset. Occasional updates – possibly by different “actors” (web, device, app), conflicts need to be prevented or resolved. Fewer creates and deletes. 90:10 Time Series Ingested (“Raw”) Very high throughout of relatively small writes. Most reads are over recent time range “slice”. Updates are rare (corrections). This category is a biggest part of the IoT application dataset. 10:90
- 35. Data Access Patterns Category Description R:W % Metadata & Profiles Devices & Users Many low latency small reads - all over the dataset. Occasional updates – possibly by different “actors” (web, device, app), conflicts need to be prevented or resolved. Fewer creates and deletes. 90:10 Time Series Ingested (“Raw”) Very high throughout of relatively small writes. Most reads are over recent time range “slice”. Updates are rare (corrections). This category is a biggest part of the IoT application dataset. 10:90 Aggregated (“Derived”) Mostly reads – users, platform services, reports. Writes are periodical on each time interval or from batch jobs. 80:20
- 36. Database Type For IoT or Time Series Relational Key Value Document Wide Column Graph MySQL Riak KV MongoDB Cassandra Neo4J PostgreSQL DynamoDB CouchBase HBase Titan Oracle Voldemort RethinkDB Accumulo Infinite Graph We need a new type of NoSQL database – Time Series None of existing DB types was designed to handle time series data • Wide column DBs have high write throughput, but reads and updates are not their strength • Key Value and Document DBs handle metadata well, but struggle with heavy writes and time-slicing reads • Relational - good with metadata (unless number of updates is high), but a bad choice for TS data • Graph DB – not a good choice for either time series or metadata, can be added later on
- 37. Database Type For IoT or Time Series Relational Key Value Document Wide Column Graph MySQL Riak KV MongoDB Cassandra Neo4J PostgreSQL DynamoDB CouchBase HBase Titan Oracle Voldemort RethinkDB Accumulo Infinite Graph Time Series InfluxDB Riak TS Blueflood KairosDB Prometeus Druid OpenTSDB Dalmatiner Graphite
- 38. Iot Sensors Data – Hot to Cold
- 39. SENSORS DATA – HOT N’ COLD Temp Purpose Description Immutable? Boiling Hot App usage Last known value(s) and/or for last N minutes, useful for immediate responses, very frequently accessed No Hot Operational dataset Last 24 hours to several days or weeks (rarely months), frequently accessed, dashboards and online analytics Almost* Warm Historical data Older data, less frequently accessed, used mostly for offline analytics and historical analysis Yes Cold Archives Used only in rare situations, kept in long term storage for regulatory or unpredicted purposes Yes
- 40. STORAGE TIERS – FROM HOT TO COLD RAM → Database (TSDB) → Object Storage → Archive Data Lake Temp Purpose Storage Products Immutable? Boiling Hot App usage Internal app cache, Redis or Memcached No Hot Operational dataset NoSQL Database (preferably Time Series DB) Riak TS, OpenTSDB, KairosDB, Cassandra, HBase Almost* Warm Historical data Object storage – HDFS (Hadoop), Ceph, Minio, Riak S2 or AWS S3 Yes Cold Archives Various Yes
- 41. STORAGE TIERS – REALITY CHECK RAM → Database (TSDB) → Object Storage → Archive Elastic Cache (Redis) → Database (Postgres, DynamoDB) → AWS S3 → Glacier Data Lake Temp AWS Service Storage price, GB per month Boiling Hot Elastic Cache (Redis) $15-45 Hot DynamoDB RDS (Postgres) $ 0.25-0.35 (SSD) from $0.1 (Magnetic) Warm Simple Storage Service (S3) $0.024 to $0.030 Cold Glacier $0.007
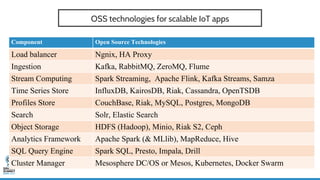
- 42. OSS technologies for scalable IoT apps Component Open Source Technologies Load balancer Ngnix, HA Proxy Ingestion Kafka, RabbitMQ, ZeroMQ, Flume Stream Computing Spark Streaming, Apache Flink, Kafka Streams, Samza Time Series Store InfluxDB, KairosDB, Riak, Cassandra, OpenTSDB Profiles Store CouchBase, Riak, MySQL, Postgres, MongoDB Search Solr, Elastic Search Object Storage HDFS (Hadoop), Minio, Riak S2, Ceph Analytics Framework Apache Spark (& MLlib), MapReduce, Hive SQL Query Engine Spark SQL, Presto, Impala, Drill Cluster Manager Mesosphere DC/OS or Mesos, Kubernetes, Docker Swarm
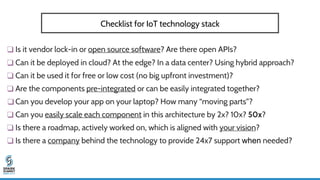
- 43. ❑ Is it vendor lock-in or open source software? Are there open APIs? ❑ Can it be deployed in cloud? At the edge? In a data center? Using hybrid approach? ❑ Can it be used it for free or low cost (no big upfront investment)? ❑ Are the components pre-integrated or can be easily integrated together? ❑ Can you develop your app on your laptop? How many “moving parts”? ❑ Can you easily scale each component in this architecture by 2x? 10x? 50x? ❑ Is there a roadmap, actively worked on, which is aligned with your vision? ❑ Is there a company behind the technology to provide 24x7 support when needed? Checklist for IoT technology stack
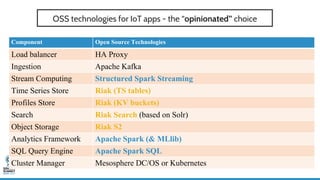
- 44. OSS technologies for IoT apps - the “opinionated” choice Component Open Source Technologies Load balancer HA Proxy Ingestion Apache Kafka Stream Computing Structured Spark Streaming Time Series Store Riak (TS tables) Profiles Store Riak (KV buckets) Search Riak Search (based on Solr) Object Storage Riak S2 Analytics Framework Apache Spark (& MLlib) SQL Query Engine Apache Spark SQL Cluster Manager Mesosphere DC/OS or Kubernetes
- 45. • Riak TS (Time Series) - highly scalable NoSQL database for IoT and Time Series … and more • Riak Spark Connector for Apache Spark • Riak Integrations with Redis and Kafka • Riak Mesos Framework (RMF) for DC/OS
- 46. Thank You! Contact me at [pavel at basho dot com]