Using Spark Streaming and NiFi for the Next Generation of ETL in the Enterprise

In recent years, big data has moved from batch processing to stream-based processing since no one wants to wait hours or days to gain insights. Dozens of stream processing frameworks exist today and the same trend that occurred in the batch-based big data processing realm has taken place in the streaming world so that nearly every streaming framework now supports higher level relational operations. On paper, combining Apache NiFi, Kafka, and Spark Streaming provides a compelling architecture option for building your next generation ETL data pipeline in near real time. What does this look like in an enterprise production environment to deploy and operationalized? The newer Spark Structured Streaming provides fast, scalable, fault-tolerant, end-to-end exactly-once stream processing with elegant code samples, but is that the whole story? We discuss the drivers and expected benefits of changing the existing event processing systems. In presenting the integrated solution, we will explore the key components of using NiFi, Kafka, and Spark, then share the good, the bad, and the ugly when trying to adopt these technologies into the enterprise. This session is targeted toward architects and other senior IT staff looking to continue their adoption of open source technology and modernize ingest/ETL processing. Attendees will take away lessons learned and experience in deploying these technologies to make their journey easier. Speaker: Andrew Psaltis, Principal Solution Engineer, Hortonworks

























































































More Related Content
What's hot (20)
Similar to Using Spark Streaming and NiFi for the Next Generation of ETL in the Enterprise (20)















![[253] apache ni fi](https://cdn.slidesharecdn.com/ss_thumbnails/235apachenifi-150915053924-lva1-app6892-thumbnail.jpg?width=560&fit=bounds)


More from DataWorks Summit (20)



















Recently uploaded (20)




















Using Spark Streaming and NiFi for the Next Generation of ETL in the Enterprise
- 1. 1 © Hortonworks Inc. 2011–2018. All rights reserved Using Spark Streaming and NiFi for the next generation of ETL in the enterprise Andrew Psaltis Regional CTO APAC
- 2. 2 © Hortonworks Inc. 2011–2018. All rights reserved Traditional ETL 1011010 DBseconds hoursFile
- 3. 3 © Hortonworks Inc. 2011–2018. All rights reserved Streaming ETL 1011010 DBseconds
- 4. 4 © Hortonworks Inc. 2011–2018. All rights reserved Reference Streaming Architecture
- 5. 5 © Hortonworks Inc. 2011–2018. All rights reserved Apache NiFi
- 6. 6 © Hortonworks Inc. 2011–2018. All rights reserved
- 7. 7 © Hortonworks Inc. 2011–2018. All rights reserved Simplistic View of Dataflows: Easy, Definitive Acquire Data Store Data Data Flow Process Analyze Data
- 8. 8 © Hortonworks Inc. 2011–2018. All rights reserved Standards: http://xkcd.com/927/
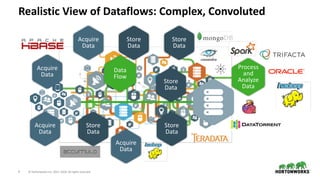
- 9. 9 © Hortonworks Inc. 2011–2018. All rights reserved Realistic View of Dataflows: Complex, Convoluted Acquire Data Store Data Acquire Data Store Data Store Data Store Data Store Data Process and Analyze Data Data Flow Acquire Data Acquire Data
- 10. 10 © Hortonworks Inc. 2011–2018. All rights reserved The National Security Agency Years • Created in 2006 • Improved over eight years • Simple initial vision – Visio for real-time dataflow management • National Security Agency donated the codebase to the ASF in late 2014
- 11. 11 © Hortonworks Inc. 2011–2018. All rights reserved Apache NiFi à Key Features • Guaranteed delivery • Data buffering - Backpressure - Pressure release • Prioritized queuing • Flow specific QoS - Latency vs. throughput - Loss tolerance • Data provenance • Supports push and pull models • Recovery/recording a rolling log of fine- grained history • Visual command and control • Flow templates • Pluggable/multi-role security • Designed for extension • Clustering
- 12. 12 © Hortonworks Inc. 2011–2018. All rights reserved Visual Command and Control • Drag and drop processors to build a flow • Start, stop, and configure components in real time • View errors and corresponding error messages • View statistics and health of data flow • Create templates of common processor & connections
- 13. 13 © Hortonworks Inc. 2011–2018. All rights reserved Provenance/Lineage
- 14. 14 © Hortonworks Inc. 2011–2018. All rights reserved Prioritization • Configure a prioritizer per connection • Determine what is important for your data – time based, arrival order, importance of a data set • Funnel many connections down to a single connection to prioritize across data sets • Develop your own prioritizer if needed
- 15. 15 © Hortonworks Inc. 2011–2018. All rights reserved
- 16. 16 © Hortonworks Inc. 2011–2018. All rights reserved Latency vs. Throughput • Choose between lower latency, or higher throughput on each processor
- 17. 17 © Hortonworks Inc. 2011–2018. All rights reserved NiFi Positioning Apache NiFi / MiNiFi ETL (Informatica, etc.) Enterprise Service Bus (Fuse, Mule, etc.) Messaging Bus (Kafka, MQ, etc.) Processing Framework (Storm, Spark, etc.)
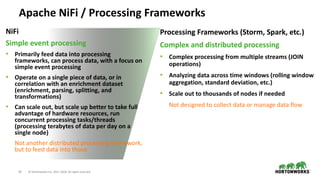
- 18. 18 © Hortonworks Inc. 2011–2018. All rights reserved Apache NiFi / Processing Frameworks NiFi Simple event processing • Primarily feed data into processing frameworks, can process data, with a focus on simple event processing • Operate on a single piece of data, or in correlation with an enrichment dataset (enrichment, parsing, splitting, and transformations) • Can scale out, but scale up better to take full advantage of hardware resources, run concurrent processing tasks/threads (processing terabytes of data per day on a single node) Not another distributed processing framework, but to feed data into those Processing Frameworks (Storm, Spark, etc.) Complex and distributed processing • Complex processing from multiple streams (JOIN operations) • Analyzing data across time windows (rolling window aggregation, standard deviation, etc.) • Scale out to thousands of nodes if needed Not designed to collect data or manage data flow
- 19. 19 © Hortonworks Inc. 2011–2018. All rights reserved Apache NiFi / Messaging Bus Services NiFi Provide dataflow solution • Centralized management, from edge to core • Great traceability, event level data provenance starting when data is born • Interactive command and control – real time operational visibility • Dataflow management, including prioritization, back pressure, and edge intelligence • Visual representation of global dataflow Not a messaging bus, flow maintenance needed when you have frequent consumer side updates Messaging Bus (Kafka, JMS, etc.) Provide messaging bus service • Low latency • Great data durability • Decentralized management (producers & consumers) • Low broker maintenance for dynamic consumer side updates Not designed to solve dataflow problems (prioritization, edge intelligence, etc.) Traceability limited to in/out of topics, no lineage Lack of global view of components/connectivities
- 20. 20 © Hortonworks Inc. 2011–2018. All rights reserved Apache NiFi / Integration, or ingestion, Frameworks NiFi End user facing dataflow management tool • Out of the box solution for dataflow management • Interactive command and control in the core, design and deploy on the edge • Flexible failure handling at each point of the flow • Visual representation of global dataflow and connectivities • Native cross data center communication • Data provenance for traceability Not a library to be embedded in other applications Integration framework (Spring Integration, Camel, etc), ingestion framework (Flume, etc) Developer facing integration tool with a focus on data ingestion • A set of tools to orchestrate workflow • A fixed design and deploy pattern • Leverage messaging bus across disconnected networks Developer facing, custom coding needed to optimize Pre-built failure handling, lack of flexibility No holistic view of global dataflow No built-in data traceability
- 21. 21 © Hortonworks Inc. 2011–2018. All rights reserved Apache NiFi / ETL Tools NiFi NOT schema dependent • Dataflow management for both structured and unstructured data, powered by separation of metadata and payload • Schema is not required, but you can have schema • Minimum modeling effort, just enough to manage dataflows • Do the plumbing job, maximize developers’ brainpower for creative work Not designed to do heavy lifting transformation work for DB tables (JOIN datasets, etc.). You can create custom processors to do that, but long way to go to catch up with existing ETL tools from user experience perspective (GUI for data wrangling, cleansing, etc.) ETL (Informatica, etc.) Schema dependent • Tailored for Databases/WH • ETL operations based on schema/data modeling • Highly efficient, optimized performance Must pre-prepare your data, time consuming to build data modeling, and maintain schemas Not geared towards handling unstructured data, PDF, Audio, Video, etc. Not designed to solve dataflow problems
- 22. 22 © Hortonworks Inc. 2011–2018. All rights reserved NiFi Big Picture Pattern: Diverse Flows from One Tool “Swiss Army Knife of Data Movement”
- 23. 23 © Hortonworks Inc. 2011–2018. All rights reserved Apache Kafka
- 24. 24 © Hortonworks Inc. 2011–2018. All rights reserved
- 25. 25 © Hortonworks Inc. 2011–2018. All rights reserved What is Apache Kafka? • Distributed streaming platform that allows publishing and subscribing to streams of records • Streams of records are organized into categories called topics • Topics can be partitioned and/or replicated • Records consist of a key, value, and timestamp http://kafka.apache.org/intro Kafka Cluster producer producer producer consumer consumer consumer APACHE KAFKA High throughput, distributed system. Designed to operate at large scale.
- 26. 26 © Hortonworks Inc. 2011–2018. All rights reserved Why Kafka Source System Source System Source System Source System Kafka Hadoop Security Systems Real-Time Monitoring Data Warehouse Producers Brokers Consumers Kafka decouples data pipelines
- 27. 27 © Hortonworks Inc. 2011–2018. All rights reserved Overview of Topics • Topics are a partitioned ordered, immutable sequence of messages • Messages are retained for a configurable amount of time (24 hours, 7 days, etc.) • Each consumer retains its own offset in the partition
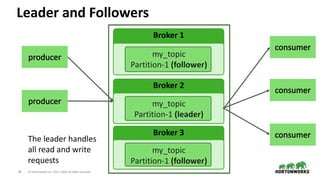
- 28. 28 © Hortonworks Inc. 2011–2018. All rights reserved Understanding Partitions • Partitions are an ordered, immutable sequence of messages • Each partition is replicated for fault tolerance • A replicated partition has one broker that acts as the leader and the rest as followers
- 29. 29 © Hortonworks Inc. 2011–2018. All rights reserved Publishing Messages message_a message_b message_c message_d message_e message_f 1. A producer publishes messages to a topic 2. The producer decides which partition to send each message to offset -> 0 1 2 3 4 Partition 0 message_b message_f Partition 1 message_a message_c message_e Partition 2 message_d Old New 3. New messages are written to the end of the partition 4. A consumer fetches messages from a partition by specifying an offset
- 30. 30 © Hortonworks Inc. 2011–2018. All rights reserved Leader and Followers Broker 1 my_topic Partition-1 (follower) Broker 2 my_topic Partition-1 (leader) Broker 3 my_topic Partition-1 (follower) The leader handles all read and write requests
- 31. 31 © Hortonworks Inc. 2011–2018. All rights reserved Consuming Messages • Messages are consumed in Kafka by a consumer group • Each individual consumer is labeled with a group name • Each message in a topic is sent to one consumer in the group
- 32. 32 © Hortonworks Inc. 2011–2018. All rights reserved Consumer Groups Broker 1 my_topic: Partition-0 my_topic: Partition-3 Broker 2 my_topic: Partition-1 my_topic: Partition-2 Consumer Group A consumer consumer consumer consumer Consumer Group B consumer consumer consumer consumer consumer message_1 Each message is consumed by one consumer per group
- 33. 33 © Hortonworks Inc. 2011–2018. All rights reserved Spark Structured Streaming
- 34. 34 © Hortonworks Inc. 2011–2018. All rights reserved What is Real-Time?
- 35. 35 © Hortonworks Inc. 2011–2018. All rights reserved Thinking about time
- 36. 36 © Hortonworks Inc. 2011–2018. All rights reserved
- 37. 37 © Hortonworks Inc. 2011–2018. All rights reserved Time Skew
- 38. 38 © Hortonworks Inc. 2011–2018. All rights reserved Windows
- 39. 39 © Hortonworks Inc. 2011–2018. All rights reserved Tumbling Windows
- 40. 40 © Hortonworks Inc. 2011–2018. All rights reserved Tumbling Time Windowing
- 41. 41 © Hortonworks Inc. 2011–2018. All rights reserved Tumbling Count Windowing
- 42. 42 © Hortonworks Inc. 2011–2018. All rights reserved Sliding Windows
- 43. 43 © Hortonworks Inc. 2011–2018. All rights reserved Sliding Time Window
- 44. 44 © Hortonworks Inc. 2011–2018. All rights reserved Sliding Count Window
- 45. 45 © Hortonworks Inc. 2011–2018. All rights reserved Watermarking • The threshold of how late data is expected to be and when to drop old state • Trails behind max event time seen by the Spark engine • Easiest to think of the Watermark delay as the trailing gap
- 46. 46 © Hortonworks Inc. 2011–2018. All rights reserved Watermarking • Data that is newer than the watermark is late, but allowed to aggregate • Data that is older than the watermark is dropped as it’s "too late" • Any windows older than watermark are automatically deleted to limit state
- 47. 47 © Hortonworks Inc. 2011–2018. All rights reserved Structured Streaming Turns stream processing into SQL fast, scalable, fault-tolerant Unifies high level APIs with Spark deal with complex data and complex workloads
- 48. 48 © Hortonworks Inc. 2011–2018. All rights reserved Source: http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
- 49. 49 © Hortonworks Inc. 2011–2018. All rights reserved Source: http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
- 50. 50 © Hortonworks Inc. 2011–2018. All rights reserved Source: http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
- 51. 51 © Hortonworks Inc. 2011–2018. All rights reserved Source: http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
- 52. 52 © Hortonworks Inc. 2011–2018. All rights reserved Source: http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
- 53. 53 © Hortonworks Inc. 2011–2018. All rights reserved Source: http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
- 54. 54 © Hortonworks Inc. 2011–2018. All rights reserved
- 55. 55 © Hortonworks Inc. 2011–2018. All rights reserved The Do’s and Don’ts
- 56. 56 © Hortonworks Inc. 2011–2018. All rights reserved The Good, The Bad, The Ugly • Use NiFi for all ingestion and data preparationAcquire Data Store Data Data Flow Process Analyze Data Acquire Data Store Data Acquire Data Store Data Store Data Store Data Store Data Process and Analyze Data Data Flow Acquire Data Acquire Data
- 57. 57 © Hortonworks Inc. 2011–2018. All rights reserved The Good, The Bad, The Ugly • Be very cautious of forcing order in Kafka
- 58. 58 © Hortonworks Inc. 2011–2018. All rights reserved The Good, The Bad, The Ugly • Chose your data store to match your query pattern
- 59. 59 © Hortonworks Inc. 2011–2018. All rights reserved The Good, The Bad, The Ugly • Chose your data store to match your query pattern
- 60. 60 © Hortonworks Inc. 2011–2018. All rights reserved The Good, The Bad, The Ugly • Monitor, Monitor, Monitor • Think about using schemas • Plan for spike in traffic – this impacts Kafka portioning and consumers
- 61. 61 © Hortonworks Inc. 2011–2018. All rights reserved Questions?
- 62. 62 © Hortonworks Inc. 2011–2018. All rights reserved Thank you