Using the right data model in a data mart
28 likes20,495 views

A presentation describing how to choose the right data model design for your data mart. Discusses the pros and benefits of different data models with different rdbms technologies and tools







































![[Oracle DBA & Developer Day 2016] しばちょう先生の特別講義!!ストレージ管理のベストプラクティス ~ASMからExada...](https://cdn.slidesharecdn.com/ss_thumbnails/mktgdd2-3stragemanagementfordl2-200702092359-thumbnail.jpg?width=560&fit=bounds)















Ad
More Related Content
What's hot (20)
Viewers also liked (20)


















Ad
Similar to Using the right data model in a data mart (20)




















Ad
More from David Walker (20)




















Recently uploaded (20)




















Using the right data model in a data mart
- 1. USING THE RIGHT DATA MODEL IN A DATA MART D AV I D M WA L K E R D ATA M A N A G E M E N T & WA R E H O U S I N G
- 2. INTRODUCTION • The concept of a Data Mart as the data access interface layer for Business Intelligence has been around for over 25 years • Kimball style Dimensional Modelling and Star Schemas have become the de facto data modelling technique for data marts • These have been and continue to be hugely successful with relational databases and reporting tools – but are they the right tool for todays technologies ? March 2012 © 2012 Data Management & Warehousing 2
- 3. WHY IS A STAR SCHEMA SO SUCCESSFUL? • There are three main reasons for creating a star schema and their wide acceptance as a technique • Simpler for users to understand • Highly performant user queries • Optimal disk storage usage March 2012 © 2012 Data Management & Warehousing Slide 3
- 4. WHAT IS A STAR SCHEMA? • A star schema consists of DATE DIMENSION STORE DIMENSION two parts • • Date Surrogate Key Date • • Store Surrogate Key Store Name • Facts: • Day • Store Number Measurable numeric and/or • Month Year • Store Postcode • • Store Town time data about an event • Public Holiday Flag • Store Region • Dimensions: Descriptive attributes about SALES FACTS the event that give the facts a • Date Surrogate Key context • Store Surrogate Key • Facts are stored at a • • Customer Surrogate Key Product Surrogate Key uniform level of detail • • Sale Time Sale Quantity known as the grain of the • Sale Unit Price data • A star schema consists of a CUSTOMER DIMENSION PRODUCT DIMENSION fact table and a number of • Customer Surrogate Key Customer Loyalty Number • Product Surrogate Key Product SKU associated dimension tables • • • Customer Gender • Product Name • Customer Postcode • Product Category • Customer Town • Product Group • Customer Region • Temperature Group March 2012 © 2012 Data Management & Warehousing Slide 4
- 5. STAR SCHEMAS: SIMPLER FOR USERS TO UNDERSTAND • Intuitive grouping of select P.PRODUCT_CATEGORY, sum(SALES_QUANTITY) information from SALES_FACTS F, • e.g. All customer data in one DATE_DIMENSION D, dimension, all store data in STORE_DIMENSION S, another, etc. CUSTOMER_DIMENSION C, PRODUCT_DIMENSION P • Much easier queries than on where MONTH = ‘March’ a full relational schemas and YEAR = ‘2012’ • Consequently harder to get and CUSTOMER_GENDER = ‘Female’ the wrong answer because of and STORE_LOCATION = ‘South West’ the wrong join and F.DATE_SKEY = D.DATE_SKEY and F.STORE_SKEY = S.STORE_SKEY • All data is at the same level and F.CUSTOMER_SKEY = C.CUSTOMER_SKEY and F.PRODUCT_SKEY = P.PRODUCT_SKEY of granularity • Consequently harder to get Example query to get the number of sales in each the wrong answer because of product category for March 2012 by female mismatched levels of data customers in stores in the South West region March 2012 © 2012 Data Management & Warehousing Slide 5
- 6. STAR SCHEMAS: HIGHLY PERFORMANT USER QUERIES • Dimensional data has DATE DIMENSION STORE DIMENSION an enforced one-to- • • Date Surrogate Key Date • • Store Surrogate Key Store Name many relationship with • • Day Month • • Store Number Store Postcode the fact table • • Year Public Holiday Flag • • Store Town Store Region • Filtering occurs on the (smaller) dimensions • SALES FACTS Date Surrogate Key • e.g. • Store Surrogate Key Customer Surrogate Key where YEAR = ‘2012’ • • Product Surrogate Key Sale Time • Aggregation takes • • Sale Quantity place only on the • Sale Unit Price relevant subset of the CUSTOMER DIMENSION PRODUCT DIMENSION facts • • Customer Surrogate Key Customer Loyalty Number • • Product Surrogate Key Product SKU • e.g. • Customer Gender Customer Postcode • Product Name Product Category sum (SALES_QUANTITY) • • • Customer Town • Product Group • Customer Region • Temperature Group March 2012 © 2012 Data Management & Warehousing Slide 6
- 7. STAR SCHEMAS: OPTIMAL DISK STORAGE USAGE • If STORE_REGION had: • DATE DIMENSION Date Surrogate Key • STORE DIMENSION Store Surrogate Key • 10 discreet values • • Date Day • • Store Name Store Number • was stored in the example • • Month Year • • Store Postcode Store Town SALES_FACT table • Public Holiday Flag • Store Region • was on average 10 bytes SALES FACTS long • Date Surrogate Key • This one field alone would • • Store Surrogate Key Customer Surrogate Key require an additional 1Tb • • Product Surrogate Key Sale Time of storage • • Sale Quantity Sale Unit Price • Not storing it in the fact also improves query CUSTOMER DIMENSION PRODUCT DIMENSION performance by reducing • • Customer Surrogate Key Customer Loyalty Number • • Product Surrogate Key Product SKU disk I/O required to • • Customer Gender Customer Postcode • • Product Name Product Category retrieve the information • Customer Town • Product Group • Customer Region • Temperature Group March 2012 © 2012 Data Management & Warehousing 7
- 8. SCHEMAS: THE ALTERNATIVES RELATIONAL SNOWFLAKE STAR RESULT SET Complexity Complexity Complexity Complexity Speed Speed Speed Speed Space Space Space Space Usually used for data Favours saving some De facto standard Large single table warehouses rather space in exchange for data mart design with the entire result than data marts. for added user query based on traditional set – optimal in some Favoured solution on complexity – usually technologies. Also circumstances MPP technologies a techie compromise used as source for due to their power OLAP cubes © 2012 Data Management & Warehousing 8
- 9. STAR SCHEMAS: TECHNOLOGY ASSUMPTIONS • There are two major and often unspoken assumptions about the technologies used to build this sort of environment: • Firstly: The database used is a row store database and not a column store database • Secondly: That users will be running reporting tools and OLAP cubes to access the data • Neither of these assumptions is necessarily true – the last 10 years have seen massive innovation in Business Intelligence technologies that will have an impact on the chosen architectural solution – using alternate technologies means that you should challenge existing designs and embrace appropriate new designs in order to exploit the technology March 2012 © 2012 Data Management & Warehousing 9
- 10. UNDERSTAND THE DESIGN IMPACT OF ALTERNATE TECHNOLOGIES • Column Store Databases: • What is a column store database? • Why are column store databases efficient? • How does this affect data mart design? • The use of alternate reporting mechanisms: • The user requirement gap • How users have filled the gap March 2012 © 2012 Data Management & Warehousing Slide 10
- 11. WHAT IS A COLUMN STORE DATABASE? • Traditionally databases are ‘row-based’ i.e. each field of data in a record is stored next to each other: Forename Surname Gender David Walker Male Helen Walker Female Sheila Jones Female • Column store databases store the values in columns and then hold a mapping to form the record • This is transparent to the user, who queries a table with SQL in exactly the same way as they would a row-based database Jan 2012 © 2012 Data Management & Warehousing 11
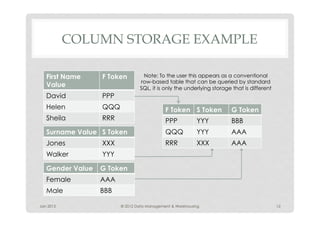
- 12. COLUMN STORAGE EXAMPLE First Name F Token Note: To the user this appears as a conventional row-based table that can be queried by standard Value SQL, it is only the underlying storage that is different David PPP Helen QQQ F Token S Token G Token Sheila RRR PPP YYY BBB Surname Value S Token QQQ YYY AAA Jones XXX RRR XXX AAA Walker YYY Gender Value G Token Female AAA Male BBB Jan 2012 © 2012 Data Management & Warehousing 12
- 13. EFFICIENCIES OF COLUMN STORE DATABASES • Column store databases offer significant storage optimisation opportunities because long strings are not repeatedly stored • In addition it is possible to compress the data column stores very efficiently • It is possible, in some column store implementations, that the column storage holds additional metadata that can be used to speed up specific queries (e.g. the number of records associated with each value in a column) • Reduced the data volume stored means reduced I/O when querying the database, this therefore also gives query performance improvements Jan 2012 © 2012 Data Management & Warehousing 13
- 14. COLUMN STORE DATABASES AND DATA MART SCHEMAS • A column store database effectively internally creates a star schema of every field in a result set table. • This minimises the storage and maximises the query speed in this type of database • Creating a star schema at the table level effectively duplicates (in a less efficient manner) the underlying structure that is automatically created by the database engine • Consequently a single table result set is more efficient in a column store database than a star schema March 2012 © 2012 Data Management & Warehousing Slide 14
- 15. SCHEMAS: THE ALTERNATIVES ROW DB COLUMN DB ROW DB COLUMN DB Complexity Complexity Complexity Complexity Speed Speed Speed Speed Space Space Space Space Column Store Column Store Database improve Databases will space usage and significantly improve increase speed space usage and compared to Row s p e e d w h e n Based Databases compared to Row Based Databases STAR SCHEMA RESULT SET SCHEMA © 2012 Data Management & Warehousing 15
- 16. WHO ARE THE COLUMN STORE VENDORS • Many of the major database vendors have bought into this concept, mostly by acquisition Vendor Database SQL Dialect Actian Vectorwise Ingres EMC Greenplum Postgres HP Vertica Postgres InfoBright InfoBright MySQL ParAccel ParAccel Postgres SAP HANA (In Memory) SAP Sybase IQ Sybase/TSQL Teradata AsterData Postgres • There are multiple other players • For more information: Wikipedia & DBMS2 March 2012 © 2012 Data Management & Warehousing 16
- 17. REPORTING TECHNOLOGIES • Historically: • Reporting tools were initially designed to provide a ‘simplified’ user interface for reporting against relational schemas rather than writing SQL • Schemas were simplified into star schemas and specialist tools evolved to query both star schemas and OLAP cubes built on top of the star schemas • The focus of the tools was on the ability to report what had happened from the data March 2012 © 2012 Data Management & Warehousing 17
- 18. THE USER REQUIREMENT GAP What users had: What users want: Historical Predictive Reporting Analytics Insight into Understanding what has what is likely happened to happen March 2012 © 2012 Data Management & Warehousing Slide 18
- 19. HOW USERS HAVE FILLED THE GAP • Spreadsheets • Users love them even if IT hate the associated data integrity issues • Users have adopted the idea of manipulating a worksheet of data equivalent to a result set table. • Spreadsheets can connect to database sources to get data often using a ‘join all’ view over a star schema to access data • Desktop based spreadsheets now support large data sets (e.g. Excel supports 1M rows, 16K columns) • Emergence or equivalent web based technologies (e.g. Google Docs) • Emergence of low cost, open source equivalents • In-built graphing and charting capabilities March 2012 © 2012 Data Management & Warehousing 19
- 20. HOW USERS HAVE FILLED THE GAP • Statistical Analysis Tools • Statistical analysis of data to identify future trends • Extracting large result sets to the tools for analysis • Connecting to result sets in the database for direct access • Emergence of low cost, open source equivalents (R) • Emergence or equivalent web based technologies (e.g. Google Prediction, R Studio) • Predictive Model Standards (PMML) • In-built graphing and charting capabilities March 2012 © 2012 Data Management & Warehousing Slide 20
- 21. HOW USERS HAVE FILLED THE GAP • Data Visualisation/Dashboarding Tools • Multiple maps, charts, graphs, gauges, sparklines, heat maps and traffic lights displaying process critical information • Often sourced from a result set table which is being drip fed the latest data by being automatically generated by devices (machine generated data) • Emergence of agile/rapid development style tools • Tools depend on it being easy to load/update the data to give near realtime information March 2012 © 2012 Data Management & Warehousing Slide 21
- 22. SCHEMA TYPE SELECTION BASED ON IMPLEMENTATION TECHNOLOGY SPREADSHEETS DASHBOARDS STATISTICAL TOOLS Physical Star Schema with Single Table View Physical Single Table TRADITIONAL AND CUBING REPORTING TOOLS Physical Star Schema Physical Single Table with Star Schema Views ROW STORE COLUMN STORE DATABASE DATABASE March 2012 © 2012 Data Management & Warehousing Slide 22
- 23. IN CONCLUSION … • When designing your solution architecture it is important that you choose The Equivalent Alternate Design best suited to the technology you are deploying • Star Schemas are still the best design pattern to use when you are using row based databases • Result Set Single Tables are more efficient when using column store databases • Consider the users and the tools that they will use when choosing the schema design type March 2012 © 2012 Data Management & Warehousing 23
- 24. CONTACT US • Data Management & Warehousing • Website: http://www.datamgmt.com • Telephone: +44 (0) 118 321 5930 • David Walker • E-Mail: [email protected] • Telephone: +44 (0) 7990 594 372 • Skype: datamgmt • White Papers: http://scribd.com/davidmwalker March 2012 © 2012 Data Management & Warehousing 24
- 25. ABOUT US Data Management & Warehousing is a UK based consultancy that has been delivering successful business intelligence and data warehousing solutions since 1995. Our consultants have worked with major corporations around the world including the US, Europe, Africa and the Middle East. We have worked in many industry sectors such as telcos, manufacturing, retail, financial and transport. We provide governance and project management as well as expertise in the leading technologies. March 2012 © 2012 Data Management & Warehousing 25
- 26. THANK YOU © 2 0 1 2 - D ATA M A N A G E M E N T & WA R E H O U S I N G H T T P : / / W W W. D ATA M G M T. C O M