Virtual Flink Forward 2020: Netflix Data Mesh: Composable Data Processing - Justin Cunningham

Netflix processes trillions of events and petabytes of data a day in the Keystone data pipeline, which is built on top of Apache Flink. As Netflix has scaled up original productions annually enjoyed by more than 150 million global members, data integration across the streaming service and the studio has become a priority. Scalably integrating data across hundreds of different data stores in a way that enables us to holistically optimize cost, performance and operational concerns presented a significant challenge. Learn how we expanded the scope of the Keystone pipeline into the Netflix Data Mesh, our real-time, general-purpose, data transportation platform for moving data between Netflix systems. The Keystone Platform’s unique approach to declarative configuration and schema evolution, as well as our approach to unifying batch and streaming data and processing will be covered in depth.



































Recommended



























![[DSC Europe 22] Lakehouse architecture with Delta Lake and Databricks - Draga...](https://cdn.slidesharecdn.com/ss_thumbnails/draganberic-lakehousearchitecturewithdeltalakeanddatabricks-221130080712-6e817e95-thumbnail.jpg?width=560&fit=bounds)


More Related Content
What's hot (20)
Similar to Virtual Flink Forward 2020: Netflix Data Mesh: Composable Data Processing - Justin Cunningham (20)


















More from Flink Forward (20)




















Recently uploaded (20)




















Virtual Flink Forward 2020: Netflix Data Mesh: Composable Data Processing - Justin Cunningham
- 1. Netflix Data Mesh Composable Data Processing [email protected]
- 5. More than 150M Global Members Trillions of Messages / Petabytes a Day
- 6. A high level view of Netflix’s Studio Structure
- 7. Airport: Netflix Air Traffic Control: Studio Airplanes: Productions Credit: Christopher Goss, Netflix
- 9. Production Company D Production Company E Studio B Studio A Production Company F Studio C Parent Studio (many airports, many airplanes per airport)
- 10. Netflix (one large airport, huge # of airplanes)
- 12. Data Mesh: Composable Data Processing Data Transport Problems Significant duplication of effort across pipelines and teams. Delay in bringing online new pipelines and increasing maintenance overhead from existing pipeline. Uneven implementation of best practices. Need for lower latency data transportation and warehousing for operational reporting. Correctness issues related to distributed systems error recovery.
- 13. Data Mesh: Composable Data Processing Flink Processing RDS Cassandra Airtable Logging Data … RDS Cassandra S3 Data Warehouse Elastic Search … Extract Transform Load
- 14. Data Mesh: Composable Data Processing Stream 1 Stream 2 Stream 3 Stream 4 Catalog EV Cache ES S3 Service RDS Cassandra Stream Processor SourceConnector SourceConnector Sources Sinks SinkConnector SinkConnector SinkConnector Out In (Avro)
- 15. Stream 1 Stream 2 Stream 1 Stream Processor Stream Processor Streams Sinks Data Mesh: Composable Data Processing
- 23. Data Mesh: Composable Data Processing Source Database DB CDC Source Connector DB Change Stream CDC Flink Auditor GraphQL Flink Processor Enriched Stream Iceberg Sink Flink Processor Iceberg S3 Data GraphQL Flink Auditor Batch Iceberg Auditor
- 25. Data Mesh: Composable Data Processing Overall Schema Evolution Approach Apache Avro schema format Stream processors are deployed with fixed input and output schemas Schema changes are managed by redeploying with new fixed input and output schemas Processors can opt-in to Automatic schema upgrades Most schema changes don’t require a topic change
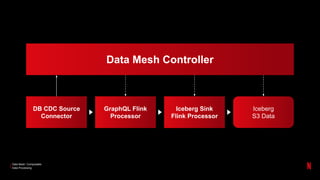
- 26. Data Mesh: Composable Data Processing Data Mesh Controller DB CDC Source Connector GraphQL Flink Processor Iceberg Sink Flink Processor Iceberg S3 Data
- 27. Data Mesh Batch & Stream Convergence
- 28. Data Mesh: Composable Data Processing
- 29. Physical Data Mesh Storage id: name 1: id 2: first 3: last Physical S3 Storage id 1 2 3 Iceberg Data id: name 1: id 2: first 3: last Logical Iceberg Avro Data Mesh Topic Avro Iceberg Sink Data Mesh: Composable Data Processing
- 30. Physical Data Mesh Storage id: name 1: id 2: first 3: last 4: city Physical S3 Storage id 1 2 3 4 Iceberg Data id: name 1: id 2: first 3: last Logical Iceberg Avro Data Mesh Topic Avro Iceberg Sink Data Mesh: Composable Data Processing
- 31. id: name 1: id 2: first 3: last Physical Data Mesh Storage id: name 1: id 2: first 3: last 4: city Physical S3 Storage id 1 2 3 4 Iceberg Data id: name 1: id 2: first 3: last 4: city Logical Iceberg Avro Data Mesh Topic Avro Iceberg Sink Data Mesh: Composable Data Processing
- 32. Physical Data Mesh Storage id: name 1: id 2: first_name 3: last_name 4: city Physical S3 Storage id 1 2 3 4 Iceberg Data id: name 1: id 2: first 3: last 4: city Logical Iceberg Avro Data Mesh Topic Avro Iceberg Sink id: name 1: id 2: first_name 3: last_name 4: city Data Mesh: Composable Data Processing
- 33. Physical Data Mesh Storage id: name 1: id 2: first_name 4: city 5: last Physical S3 Storage id 1 2 3 4 5 Iceberg Data id: name 1: id 2: first_name 4: city 5: last id: name 1: id 2: first_name 3: last_name 4: city id: name 1: id 2: first 3: last 4: city Logical Iceberg Avro Data Mesh Topic Avro Iceberg Sink Data Mesh: Composable Data Processing
- 34. Data Mesh: Composable Data Processing