Virtualizing Apache Spark with Justin Murray

This talk explains the reasons why virtualizing Spark, in-house or elsewhere, is a requirement in today’s fast-moving and experimental world of data science and data engineering. Different teams want to spin up a Spark cluster “on the fly” to carry out some research and quickly answer business questions. They are not concerned with the availability of the server hardware – or with what any other team might be doing on it at the time. Virtualization provides the means of working within your own sandbox to try out the new query or Machine Learning algorithm. Deep performance test results will be shown that demonstrate that Spark and ML programs perform equally well on virtual machines just like native implementations do. An early introduction is given to the best practices you should adhere to when you do this. If time allows, a short demo will be given of creating an ephemeral, single-purpose Spark cluster, running an ML application test program on that cluster, and bringing it down when finished.



















Recommended






























More Related Content
What's hot (20)
Similar to Virtualizing Apache Spark with Justin Murray (20)


















More from Databricks (20)




















Recently uploaded (20)




















Virtualizing Apache Spark with Justin Murray
- 1. Justin Murray, VMware Virtualizing Spark on VMware vSphere
- 3. Use Cases : Virtualization of Big Data • IT wants to provide Spark clusters as a service on-demand for its end users • Enterprises have development, test, pre-prod staging and production clusters that are required to be separated from each other and provisioned independently • Organizations need different versions of Spark to be available to different teams - with possibly different services available • Enterprises do not wish to dedicate a specific set of hardware to each different requirement above, and want to reduce overall costs CONFIDENTIAL 3
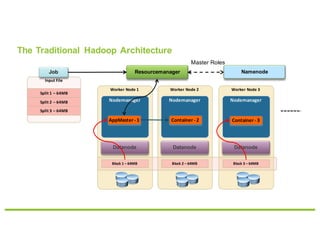
- 4. Worker Node 1 Worker Node 2 Worker Node 3 Input File The Traditional Hadoop Architecture ResourcemanagerJob Datanode Nodemanager Split 1 – 64MB AppMaster - 1 Split 2 – 64MB Split 3 – 64MB Nodemanager Nodemanager Datanode Datanode Block 1 – 64MB Block 2 – 64MB Block 3 – 64MB Container - 2 Container - 3 Master Roles Namenode
- 5. Worker Node 1 Worker Node 2 Worker Node 3 Input File Hadoop – in Virtual Machines ResourceManagerJob Datanode Nodemanager Split 1 – 64MB AppMaster - 1 Split 2 – 64MB Split 3 – 64MB Nodemanager Nodemanager Datanode Datanode Block 1 – 64MB Block 2 – 64MB Block 3 – 64MB Container - 2 Container - 3 Namenode Master Roles
- 6. Worker Node 1 Worker Node 2 Worker Node 3 The Spark Architecture – Standalone Driver Job Executor JVM Executor Executor JVM JVM Executor JVM Executor JVM Executor JVM
- 7. Worker Node 1 Worker Node 2 Worker Node 3 Spark Standalone - Virtualized Driver Job Executor JVM Executor Executor JVM JVM Executor JVM Executor JVM Executor JVM Virtual Machine
- 8. NodemanagerNodemanagerNodemanager Worker Node 1 Worker Node 2 Worker Node 3 The Spark Architecture (on YARN) Job Datanode AppMaster - 1 Datanode Datanode Block 1 – 64MB Block 2 – 64MB Block 3 – 64MB Container - 2 Container - 3 Namenode Driver Executor Executor Resourcemanager
- 10. Virtualization Host Server VMDK Hadoop Node 1 Virtual Machine Datanode Ext4 Nodemanager Ext4 Ext4 Ext4 Six or More Local DAS disksper Virtual Machine VMDK VMDK VMDK VMDK VMDK VMDK VMDK Hadoop Node 2 Virtual Machine Datanode Ext4 Nodemanager Ext4 Ext4 Ext4Ext4 VMDKVMDK VMDKVMDK Ext4Ext4Ext4 Combined Model: Two Virtual Machines on a Host
- 11. #1 Reference Architecture from Cloudera
- 12. Performance
- 13. Workloads - Spark • Two standard analytic programs from the Spark MLLib (Machine Learning Library) • Driven using SparkBench (https://github.com/SparkTC/spark-bench) – Support Vector Machine – Logistic Regression CONFIDENTIAL 13
- 14. Spark Support Vector Machine Performance CONFIDENTIAL 14
- 16. Results - Spark •Support Vector Machines workload, which stayed in memory, ran about 10% faster in virtualized form than on bare metal •Logistic Regression workload, which was written to disk at the larger dataset sizes, showed a slight advantage to bare metal •part of the dataset was cached to disk, •larger memory of the bare metal Spark executors may help •Both workloads showed linear scaling from 5 to 10 hosts and as dataset size increased CONFIDENTIAL 16
- 17. 1 TB RAM on Server Each NUMA Node has 1024/2 512GB 482 GB RAM for each VM NUMA and Virtual Machine Placement
- 18. §Spark workloads work very well on VMware vSphere • Various performance studies have shown that any difference between virtualized performance and native performance is minimal • Follow the general best practice guidelines that VMware has published • Design patterns such as data-compute separation can be used to provide elasticity of your Spark cluster. Conclusions
- 20. Add Slides as Necessary • Supporting points go here.