Volodymyr Lyubinets "Introduction to big data processing with Apache Spark"
Download as PPTX, PDF1 like346 views

The document provides an overview of Databricks, a company founded by the creators of Apache Spark, highlighting their contributions to Spark and its applications in big data. It discusses the evolution of data processing frameworks from Google’s MapReduce to Hadoop and subsequently to Spark, emphasizing Spark’s efficiency and use cases in various data-heavy applications. Additionally, it covers programming aspects of Spark, including RDDs, DataFrames, optimizations, and practical examples such as tweet analysis.
















![Writing Spark programs - RDD
scala> val rdd = sc.parallelize(List(1,
2, 3))
rdd: org.apache.spark.rdd.RDD[Int] =
ParallelCollectionRDD[1] at parallelize
at <console>:27
scala> rdd.count()
res1: Long = 3
18](https://image.slidesharecdn.com/sparkminsk-170413141727/85/Volodymyr-Lyubinets-Introduction-to-big-data-processing-with-Apache-Spark-18-320.jpg)
![Writing Spark programs - RDD
scala> rdd.collect()
res8: Array[Int] = Array(1, 2, 3)
scala> rdd.map(x => 2 * x).collect()
res2: Array[Int] = Array(2, 4, 6)
scala> rdd.filter(x => x % 2 ==
0).collect()
res3: Array[Int] = Array(2)
19](https://image.slidesharecdn.com/sparkminsk-170413141727/85/Volodymyr-Lyubinets-Introduction-to-big-data-processing-with-Apache-Spark-19-320.jpg)


![Writing Spark programs: ML
22
# Every record of this DataFrame contains the label and
# features represented by a vector.
df = sqlContext.createDataFrame(data, ["label", "features"])
# Set parameters for the algorithm.
lr = LogisticRegression(maxIter=10)
# Fit the model to the data.
model = lr.fit(df)
# Given a dataset, predict each point's label, and show the results.
model.transform(df).show()](https://image.slidesharecdn.com/sparkminsk-170413141727/85/Volodymyr-Lyubinets-Introduction-to-big-data-processing-with-Apache-Spark-22-320.jpg)






















Volodymyr Lyubinets "Introduction to big data processing with Apache Spark"
- 2. Myself Databricks 2 About the speaker • Company founded by creators of Apache Spark • Remains the largest contributor to Spark and builds the platform to make working with Spark easy. • Raised over 100M USD in funding • Software Engineer at Databricks • Previously interned at a Facebook, LinkedIn, etc. • Competitive programmer, red on TopCoder, 13th at ACM ICPC finals
- 3. Big Data - why you should care • Data grows faster than computing power 3
- 4. Some big data use cases • Log mining and processing. • Recommendation systems. • Palantir’s solution for small businesses. 4
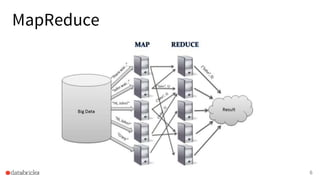
- 5. How it all started • In 2004 Google published the MapReduce paper. • In 2006 Hadoop was started, soon adopted by Yahoo. 5
- 6. MapReduce 6
- 7. MapReduce 7
- 8. Map 8 public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } }
- 9. Reduce 9 public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
- 10. Recommender systems at LinkedIn • Pipeline of nearly 80 individual jobs. • Various data formats: json, binary json, avro, etc. • Entire pipeline took around 7 hours. • LinkedIn used in-house solutions (e.g. Azkaban for scheduling, own HDFS).
- 11. Problems • Interactively checking data was inconvenient. • Slow - not even close to realtime. • Problems working with some formats - as a result an extra job was required to convert them. • Some jobs were a “one-liner” and could have been avoided.
- 12. How it all started • In 2012 Spark was created as a research project at Berkeley to address shortcomings of Hadoop MapReduce. 12
- 13. What’s Apache Spark? Spark is a framework for doing distributed computations on a cluster. 13
- 14. Large Scale Usage: Largest cluster: 8000 nodes Largest single job: 1 petabyte Top streaming intake: 1 TB/hour 2014 on-disk 100 TB sort record: 23 mins / 207 EC2 nodes
- 15. Writing Spark programs - RDD • Resilient Distributed Dataset • Basically a collection of data that is spread across many computers. • Can be thought of as list that doesn’t allow random access. • RDDs built and manipulated through a diverse set of parallel transformations (map, filter, join) and actions (count, collect, save) • RDDs automatically rebuilt on machine failure 15
- 16. map() intersection() cartesian() flatMap() distinct() pipe() filter() groupByKey() coalesce() mapPartitions() reduceByKey() repartition() mapPartitionsWithIndex() sortByKey() partitionBy() sample() join() ... union() cogroup() ... Transformations (lazy)
- 17. reduce() takeOrdered() collect() saveAsTextFile() count() saveAsSequenceFile() first() saveAsObjectFile() take() countByKey() takeSample() foreach() saveToCassandra() ... Actions
- 18. Writing Spark programs - RDD scala> val rdd = sc.parallelize(List(1, 2, 3)) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:27 scala> rdd.count() res1: Long = 3 18
- 19. Writing Spark programs - RDD scala> rdd.collect() res8: Array[Int] = Array(1, 2, 3) scala> rdd.map(x => 2 * x).collect() res2: Array[Int] = Array(2, 4, 6) scala> rdd.filter(x => x % 2 == 0).collect() res3: Array[Int] = Array(2) 19
- 20. 1) Create some input RDDs from external data or parallelize a collection in your driver program. 1) Lazily transform them to define new RDDs using transformations like filter() or map() 1) Ask Spark to cache() any intermediate RDDs that will need to be reused. 1) Launch actions such as count() and collect() to kick off a parallel computation, which is then optimized and executed by Spark. Lifecycle of a Spark Program
- 21. Problem #1: Hadoop MR is verbose 21 text_file = sc.textFile("hdfs://...") counts = text_file.flatMap(lambda line: line.split(" ")) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b) counts.saveAsTextFile("hdfs://...")
- 22. Writing Spark programs: ML 22 # Every record of this DataFrame contains the label and # features represented by a vector. df = sqlContext.createDataFrame(data, ["label", "features"]) # Set parameters for the algorithm. lr = LogisticRegression(maxIter=10) # Fit the model to the data. model = lr.fit(df) # Given a dataset, predict each point's label, and show the results. model.transform(df).show()
- 23. Problem #2: Hadoop MR is slow •Spark is 10-100x times faster than MR •Hadoop MR uses checkpointing to achieve resiliency, Spark uses lineage. 23
- 25. Other Spark optimizations: DataFrame API val users = spark.sql(“select * from users”) val massUsers = users(users(“country”) === “NL”) massUsers.count() massUsers.groupBy(“name”).avg(“age”) ^ Expression AST
- 26. Other Spark optimizations: DataFrame API
- 27. Other Spark optimizations: DataFrame API
- 28. Other Spark optimizations • Dataframe operations are executed in Scala even if you run them in Python/R.
- 29. Other Spark optimizations • Project Tungsten
- 30. Other Spark optimizations • Project Tungsten (simple aggregation)
- 31. Other Spark optimizations • Query optimization (taking advantage of lazy computation)
- 32. 32 joined = users.join(events, users.id == events.uid) filtered = joined.filter(events.date >= "2015-01-01") Plan Optimization & Execution logical plan filter join scan (users) scan (events)
- 33. 33 logical plan filter join scan (users) scan (events) this join is expensive → joined = users.join(events, users.id == events.uid) filtered = joined.filter(events.date >= "2015-01-01") Plan Optimization & Execution
- 34. logical plan filter join scan (users) scan (events) optimized plan join scan (users) filter scan (events) joined = users.join(events, users.id == events.uid) filtered = joined.filter(events.date >= "2015-01-01") Plan Optimization & Execution
- 35. Other Spark optimizations In Spark 1.3: myRdd.toDF() or myDataframe.rdd() Convert Rows that contain Scala types to Rows that have Catalyst- approved types (e.g. Seq for arrays) and back. 35
- 36. Other Spark optimizations: toDF, rdd Approach: • Construct converter functions • Avoid using map() and etc. for operations that will be executed for each row when possible. 36
- 37. Other Spark optimizations: toDF, rdd 37
- 38. Other Spark optimizations: toDF, rdd 38
- 39. Other Spark optimizations: toDF, rdd 39
- 40. Other Spark optimizations: toDF, rdd 40
- 41. Hands-on Spark: Analyzing Brexit tweets • Let’s do some simple tweets analysis with Spark on databricks. • Try Databricks community edition at databricks.com/try-databricks 41
- 42. What Spark is used for • Interactive analysis • Extract Transform Load • Machine Learning • Streaming
- 43. Spark Caveats • collect()-ing large amount of data OOM’s the driver • Avoid cartesian products in SQL (join!) • Don’t overuse cache • If you’re using S3, don’t use s3n:// (use s3a://) • Don’t use spot instances for the driver node • Data format matters a lot
- 44. Today you’ve learned • What’s Apache Spark, what it’s used for. • How to write simple programs in Spark: what’s RDDs and dataframes. • Optimizations in Apache Spark. 44
- 45. Дзякуй за ўвагу! Volodymyr Lyubinets, [email protected] 07/04/2017