Дмитрий Кремер, МИА «Россия сегодня» (РИА Новости). «Построение новостного web-приложения на базе PostgreSQL»
1 like1,116,573 views

Документ описывает миграцию новостного приложения на базу данных PostgreSQL для Mail.ru, представляя детали работы с данными и архитектуры системы. В нем изложены требования к производительности, настройки авторизации, а также методы резервного копирования и мониторинга. Также упоминается опыт и квалификация администратора баз данных Дмитрия Кремера.














Дмитрий Кремер, МИА «Россия сегодня» (РИА Новости). «Построение новостного web-приложения на базе PostgreSQL»
- 1. Перевод новостного приложения на базу данных PostgreSQL Meetup в Mail.ru 3 ноября 2015 Дмитрий Кремер Администратор баз данных E-mail: [email protected] jabber: [email protected] #PostgreSQLRussia Title:mail.ru.eps Creator:Adobe Illustrator(R) 15.0 CreationDate:7/11/2010 LanguageLevel:2
- 2. МИА «Россия сегодня» ● Ведущее международное новостное агентство с 1941 года (тогда СовИнформБюро) ● Крупнейший поставщик новостного и медиа-контента в Российской Федерации (бренды РИА Новости и Sputnik News) ● Фотохостинг Олимпиады в Сочи 2014 ● Десятки корреспондентов по всей России ● Современные мультимедиа-прессцентры в Москве и Симферополе ● Платформы в социальных сетях ● Производство и распространение фотоконтента,инфографики,контента для мобильных приложений. Дмитрий Кремер ● Опыт работы с различными базами данных в качестве разработчика и системного администратора с 1999 года. ● Непрерывный опыт работы с БД Oracle c 2007 года ● Oracle Certified Professional 9i,10g ● Начал работать с PostgreSQL в мае 2015 года.
- 3. Особенности новостного приложения ● Работа в режиме 24/7.Прерывание работы сайтов должна стремиться к нулю. Прерывание сервисов выпуска допустимо на минуты в периоды минимальной нагрузки. ● Использование движка (структур данных и кода приложений) собственной разработки, стандартизация кодовой базы проектов. ● Трёхзвенная архитектура —бизнес-логика на сервере приложений ● Использование преимущестенно свежих данных (partitioning) ● Многоязычность (UTF-8) ● Необходимость использования полнотекстового поиска (Solr, tsearch2 и т. д.) ● Solr —поиск на сайте ● tsearch2 —поиск в редакторском интерфейсе
- 4. Требования к переводу ● Избежать деградации производительности и отказоустойчивости системы. ● Избежать существенной деградации уровня контроля над системой,мониторинга и стредств разрешения проблем (troubleshooting). ● По возможности не касаться структуры БД —одно из требований миграции. ● Все изменения должны быть максимально прозрачными для движка приложения. ● Минимизация простоя. ● Предварительная подготовка структуры БД. ● Использование собственных скриптов. ● Миграция данных + накат дэльты
- 5. Особенности конвертации БД ● Серьезное отличие средств и методик диагностики проблем и мониторинга ● Использование пула соединений pgbouncer в транзакционном режиме ● Необходимость сопоставления типов (различные варианты хранения числовых значений,дат и т.д.) ● Автоматическая конвертация исключительно структур данных без хранимых объектов. Использование Ora2Pg для получения первичного варианта структур данных. ● В исходной БД и PostgreSQL данные об объектах в словаре (dictionary и information_schema + pg_catalog) хранятся в разных регистрах.Dictionary —в верхнем, information_schema + pg_catalog —в нижнем.Поэтому использование кавычек в названиях объектов должно быть объектом пристального внимания!!!
- 6. Производительность системы ● 40+ проектов (баз данных) на одном сервере БД. ● 124 миллиона транзакций в сутки ● 8 тысяч запросов в секунду ● 1200 DML операций в секунду ● 300+ vacuum операций в сутки ● Среднее время запросов 5ms
- 7. Особенности настройки БД ● Авторизация и аутентификация пользователей ● Настройка autovacuum (согласно презентации Ильи Космодемьянского) http://www.slideshare.net/PostgreSQL-Consulting/postgresql-meetup-berlin-at-zalando-hq ● Агрессивные настройки в БД ● Понижение приоритета процесса autovacuum в операционной системе ● Настройка streaming replication ● Использование шаблонов базы данных для развёртывания стандартных проектов ● Логи пишутся на syslog-сервер
- 8. Авторизация и аутентификация пользователей ● Аутентификация пользователей через pgbouncer ● Хеши паролей пользователей хранятся не в БД,а в конфигурационном файле pgbouncer ● Пользователи с привилегиями DDL-операций соединяются с БД только локально из ssh- сессии или ssh-тунеля (поддерживается EMS SQL Manager for PostgreSQL) ● Пользователь для реплики создаётся исключительно с правами replication без права login.Это единственный пользователь,который соединяется с БД удалённо минуя pgbouncer.В pg_hba.conf соединение разрешено только между реплицируемыми нодами и сервером бэкапа. ● Авторизация пользователей ● Для приложений каждого проекта создаётся свой пользователь с минимальными привилегиями ● Для пользователей DevOps создана соответствующая роль-владелец объектов без права login от которой наследуются привилегии для конкретных пользователей
- 9. Настройка streaming replication ● Симметричная конфигурация ● Отказ от триггерного файла, ручное переключение ролей репликации, безшовный переход с мастер-сервера на сервер реплики (standby) без смены timeline ● wal_level = hot_standby wal_keep_segments = 500 hot_standby = on hot_standby_feedback = on
- 10. Backup и PITR-сервер ● Доставка wal-логов с использованием демона lsyncd и подсстемы ядра Linux обработки событий файловой системы inotify. ● После очистки каталога wal-огов на мастере демон lsyncd нужно перезапустить с проверкой очистки дочерних ssh-процессов,а лучше остановить,почистить,запустить lsyncd ● Резервное копирование с использованием pg_basebackup с опцией --xLog —создание бэкапа, готового к восстановлению. ● Полное дублирование компонентов архитектуры ● Использование Point In Time Recovery (PITR) сервера для замены функционала Oracle Flashback Database (не является аналогом этой технологии) ● Использование pg_switch_xlog() для создания точки восстановления.
- 11. Доставка wal-логов с использованием lsyncd
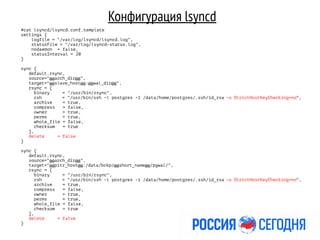
- 12. Конфигурация lsyncd #cat lsyncd/lsyncd.conf.template settings { logfile = "/var/log/lsyncd/lsyncd.log", statusFile = "/var/log/lsyncd-status.log", nodaemon = false, statusInterval = 20 } sync { default.rsync, source="@@arch_dir@@", target="@@slave_host@@:@@wal_dir@@", rsync = { binary = "/usr/bin/rsync", rsh = "/usr/bin/ssh -l postgres -i /data/home/postgres/.ssh/id_rsa -o StrictHostKeyChecking=no", archive = true, compress = false, owner = true, perms = true, whole_file = false, checksum = true }, delete = false } sync { default.rsync, source="@@arch_dir@@", target="@@pitr_host@@:/data/bckp/@@short_name@@/pgwal/", rsync = { binary = "/usr/bin/rsync", rsh = "/usr/bin/ssh -l postgres -i /data/home/postgres/.ssh/id_rsa -o StrictHostKeyChecking=no", archive = true, compress = false, owner = true, perms = true, whole_file = false, checksum = true }, delete = false }
- 13. Мониторинг и производительность ● Использование Zabbix ● За основу взят шаблон https://github.com/lesovsky/zabbix-extensions ● Доработка дискавера БД+таблица ● Использование pg_buffercache и pg_stat_statements ● Выставить параметры в postgresql.conf: shared_preload_libraries = 'pg_stat_statements' pg_stat_statements.max = 10000 pg_stat_statements.track = all ● Использование pgBadger (объём логов,ротация) ● pgBadger установлен на syslog-серверах ● Ротация логов каждый час: инкрементальное добавление данных в отчёт,ротация и сжатие часового лога
- 14. Благодарности: ● Сергею Томулевичу —за помощь в подготовке выступления ● Алексею Лесовскому —за шаблон мониторинга PostgreSQL на Zabbix ● Николаю Самохвалову —за приглашение на мероприятие в качестве спикера.
- 15. Спасибо за внимание! Вопросы? Meetup в Mail.ru 3 ноября 2015 Дмитрий Кремер Администратор баз данных E-mail: [email protected] jabber: [email protected] #PostgreSQLRussia Title:mail.ru.eps Creator:Adobe Illustrator(R) 15.0 CreationDate:7/11/2010 LanguageLevel:2