Weka presentation
Download as PPT, PDF•27 likes•32,019 views

WEKA is a collection of machine learning algorithms for data mining tasks developed in Java by the University of Waikato. It contains tools for data pre-processing, classification, regression, clustering, association rules, and feature selection. The Explorer interface in WEKA provides tools to load data, preprocess data using filters, analyze data using these machine learning algorithms, and evaluate results.
































































































Weka presentation
- 1. An Introduction to WEKA Saeed Iqbal
- 2. Content What is WEKA? Data set in WEKA The Explorer: Preprocess data Classification Clustering Association Rules Attribute Selection Data Visualization References and Resources 2 01/07/13
- 3. What is WEKA? Waikato Environment for Knowledge Analysis It’s a data mining/machine learning tool developed by Department of Computer Science, University of Waikato, New Zealand. Weka is a collection of machine learning algorithms for data mining tasks. Weka is open source software issued under the GNU General Public License. 3 01/07/13
- 4. Download and Install WEKA Website: http://www.cs.waikato.ac.nz/~ml/weka/index.html Support multiple platforms (written in java): Windows, Mac OS X and Linux Weka Manual: http://transact.dl.sourceforge.net/sourcefor ge/weka/WekaManual-3.6.0.pdf 4 01/07/13
- 5. Main Features 49 data preprocessing tools 76 classification/regression algorithms 8 clustering algorithms 3 algorithms for finding association rules 15 attribute/subset evaluators + 10 search algorithms for feature selection 5 01/07/13
- 6. Main GUI Three graphical user interfaces “The Explorer” (exploratory data analysis) “The Experimenter” (experimental environment) “The KnowledgeFlow” (new process model inspired interface) Simple CLI (Command prompt) Offers some functionality not available via the GUI 6 01/07/13
- 7. Datasets in Weka Each entry in a dataset is an instance of the java class: weka.core.Instance Each instance consists of a number of attributes Nominal: one of a predefined list of values e.g. red, green, blue Numeric: A real or integer number String: Enclosed in “double quotes” Date Relational
- 8. ARFF Files Weka wants its input data in ARFF format. A dataset has to start with a declaration of its name: @relation name @attribute attribute_name specification If an attribute is nominal, specification contains a list of the possible attribute values in curly brackets: @attribute nominal_attribute {first_value, second_value, third_value} If an attribute is numeric, specification is replaced by the keyword numeric: (Integer values are treated as real numbers in WEKA.) @attribute numeric_attribute numeric After the attribute declarations, the actual data is introduced by a tag: @data
- 9. ARFF File @relation weather @attribute outlook { sunny, overcast, rainy } @attribute temperature numeric @attribute humidity numeric @attribute windy { TRUE, FALSE } @attribute play { yes, no } @data sunny, 85, 85, FALSE, no sunny, 80, 90, TRUE, no overcast, 83, 86, FALSE, yes rainy, 70, 96, FALSE, yes rainy, 68, 80, FALSE, yes rainy, 65, 70, TRUE, no overcast, 64, 65, TRUE, yes sunny, 72, 95, FALSE, no sunny, 69, 70, FALSE, yes rainy, 75, 80, FALSE, yes sunny, 75, 70, TRUE, yes overcast, 72, 90, TRUE, yes overcast, 81, 75, FALSE, yes rainy, 71, 91, TRUE, no
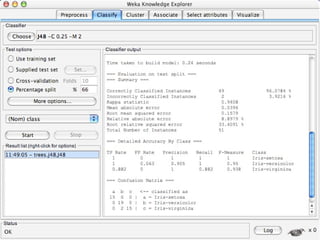
- 10. WEKA: Explorer Preprocess: Choose and modify the data being acted on. Classify: Train and test learning schemes that classify or perform regression. Cluster: Learn clusters for the data. Associate: Learn association rules for the data. Select attributes: Select the most relevant attributes in the data. Visualize: View an interactive 2D plot of the data.
- 11. Content What is WEKA? Data set in WEKA The Explorer: Preprocess data Classification Clustering Association Rules Attribute Selection Data Visualization References and Resources 11 01/07/13
- 12. Explorer: pre-processing the data Data can be imported from a file in various formats: ARFF, CSV, C4.5, binary Data can also be read from a URL or from an SQL database (using JDBC) Pre-processing tools in WEKA are called “filters” WEKA contains filters for: Discretization, normalization, resampling, attribute selection, transforming and combining attributes, … 12 01/07/13
- 13. WEKA only deals with “flat” files @relation heart-disease-simplified @attribute age numeric @attribute sex { female, male} @attribute chest_pain_type { typ_angina, asympt, non_anginal, atyp_angina} @attribute cholesterol numeric @attribute exercise_induced_angina { no, yes} @attribute class { present, not_present} @data 63,male,typ_angina,233,no,not_present 67,male,asympt,286,yes,present 67,male,asympt,229,yes,present 38,female,non_anginal,?,no,not_present ... 13 01/07/13
- 14. WEKA only deals with “flat” files @relation heart-disease-simplified @attribute age numeric @attribute sex { female, male} @attribute chest_pain_type { typ_angina, asympt, non_anginal, atyp_angina} @attribute cholesterol numeric @attribute exercise_induced_angina { no, yes} @attribute class { present, not_present} @data 63,male,typ_angina,233,no,not_present 67,male,asympt,286,yes,present 67,male,asympt,229,yes,present 38,female,non_anginal,?,no,not_present ... 14 01/07/13
- 15. load filter analyze 15 University of Waikato 01/07/13
- 16. 16 University of Waikato 01/07/13
- 17. 17 University of Waikato 01/07/13
- 18. 18 University of Waikato 01/07/13
- 19. 19 University of Waikato 01/07/13
- 20. 20 University of Waikato 01/07/13
- 21. 21 University of Waikato 01/07/13
- 22. 22 University of Waikato 01/07/13
- 23. 23 University of Waikato 01/07/13
- 24. 24 University of Waikato 01/07/13
- 25. 25 University of Waikato 01/07/13
- 26. 26 University of Waikato 01/07/13
- 27. 27 University of Waikato 01/07/13
- 28. 28 University of Waikato 01/07/13
- 29. 29 University of Waikato 01/07/13
- 30. 30 University of Waikato 01/07/13
- 31. 31 University of Waikato 01/07/13
- 32. 32 University of Waikato 01/07/13
- 33. 33 University of Waikato 01/07/13
- 34. 34 University of Waikato 01/07/13
- 35. 35 University of Waikato 01/07/13
- 36. Explorer: building “classifiers” Classifiers in WEKA are models for predicting nominal or numeric quantities Implemented learning schemes include: Decision trees and lists, instance-based classifiers, support vector machines, multi-layer perceptrons, logistic regression, Bayes’ nets, … 36 01/07/13
- 37. Decision Tree Induction: Training Dataset age income student credit_rating buys_computer <=30 high no fair no This follows <=30 high no excellent no 31…40 high no fair yes an example >40 medium no fair yes of Quinlan’s >40 low yes fair yes ID3 (Playing >40 low yes excellent no 31…40 low yes excellent yes Tennis) <=30 medium no fair no <=30 low yes fair yes >40 medium yes fair yes <=30 medium yes excellent yes 31…40 medium no excellent yes 31…40 high yes fair yes >40 medium no excellent no 37 January 7, 2013
- 38. Output: A Decision Tree for “buys_computer” age? <=30 overcast 31..40 >40 student? yes credit rating? no yes excellent fair no yes no yes 38 January 7, 2013
- 39. Algorithm for Decision Tree Induction Basic algorithm (a greedy algorithm) Tree is constructed in a top-down recursive divide-and-conquer manner At start, all the training examples are at the root Attributes are categorical (if continuous-valued, they are discretized in advance) Examples are partitioned recursively based on selected attributes Test attributes are selected on the basis of a heuristic or statistical measure (e.g., information gain) 39 January 7, 2013
- 41. 41 University of Waikato 01/07/13
- 42. 42 University of Waikato 01/07/13
- 43. 43 University of Waikato 01/07/13
- 44. 44 University of Waikato 01/07/13
- 45. 45 University of Waikato 01/07/13
- 46. 46 University of Waikato 01/07/13
- 47. 47 University of Waikato 01/07/13
- 48. 48 University of Waikato 01/07/13
- 49. 49 University of Waikato 01/07/13
- 50. 50 University of Waikato 01/07/13
- 51. 51 University of Waikato 01/07/13
- 52. 52 University of Waikato 01/07/13
- 53. 53 University of Waikato 01/07/13
- 54. 54 University of Waikato 01/07/13
- 55. 55 University of Waikato 01/07/13
- 56. 56 University of Waikato 01/07/13
- 57. 57 University of Waikato 01/07/13
- 58. 58 University of Waikato 01/07/13
- 59. 59 University of Waikato 01/07/13
- 60. 60 University of Waikato 01/07/13
- 61. 61 University of Waikato 01/07/13
- 62. 62 University of Waikato 01/07/13
- 63. Explorer: clustering data WEKA contains “clusterers” for finding groups of similar instances in a dataset Implemented schemes are: k-Means, EM, Cobweb, X-means, FarthestFirst Clusters can be visualized and compared to “true” clusters (if given) Evaluation based on loglikelihood if clustering scheme produces a probability distribution 63 01/07/13
- 64. Clustering DEMO
- 65. The K-Means Clustering Method Given k, the k-means algorithm is implemented in four steps: Partition objects into k nonempty subsets Compute seed points as the centroids of the clusters of the current partition (the centroid is the center, i.e., mean point, of the cluster) Assign each object to the cluster with the nearest seed point Go back to Step 2, stop when no more new assignment 65 January 7, 2013
- 66. Explorer: finding associations WEKA contains an implementation of the Apriori algorithm for learning association rules Works only with discrete data Can identify statistical dependencies between groups of attributes: milk, butter ⇒ bread, eggs (with confidence 0.9 and support 2000) Apriori can compute all rules that have a given minimum support and exceed a given confidence 66 01/07/13
- 67. Basic Concepts: Frequent Patterns Tid Items bought itemset: A set of one or more items 10 Beer, Nuts, Diaper k-itemset X = {x1, …, xk} 20 Beer, Coffee, Diaper (absolute) support, or, support count of X: 30 Beer, Diaper, Eggs Frequency or occurrence of an itemset 40 Nuts, Eggs, Milk X 50 Nuts, Coffee, Diaper, Eggs, Milk (relative) support, s, is the fraction of Customer Customer transactions that contains X (i.e., the buys both buys diaper probability that a transaction contains X) An itemset X is frequent if X’s support is no less than a minsup threshold Customer buys beer 67 January 7, 2013
- 68. Basic Concepts: Association Rules Tid Items bought Find all the rules X Y with minimum 10 Beer, Nuts, Diaper support and confidence 20 Beer, Coffee, Diaper 30 Beer, Diaper, Eggs support, s, probability that a 40 Nuts, Eggs, Milk transaction contains X ∪ Y 50 Nuts, Coffee, Diaper, Eggs, Milk confidence, c, conditional probability Customer Customer that a transaction having X also buys both buys contains Y diaper Let minsup = 50%, minconf = 50% Freq. Pat.: Beer:3, Nuts:3, Diaper:4, Eggs:3, {Beer, Diaper}:3 Customer buys beer Association rules: (many more!) Beer Diaper (60%, 100%) Diaper Beer (60%, 75%) 68 January 7, 2013
- 70. 70 University of Waikato 01/07/13
- 71. 71 University of Waikato 01/07/13
- 72. 72 University of Waikato 01/07/13
- 73. 73 University of Waikato 01/07/13
- 74. 74 University of Waikato 01/07/13
- 75. Explorer: attribute selection Panel that can be used to investigate which (subsets of) attributes are the most predictive ones Attribute selection methods contain two parts: A search method: best-first, forward selection, random, exhaustive, genetic algorithm, ranking An evaluation method: correlation-based, wrapper, information gain, chi-squared, … Very flexible: WEKA allows (almost) arbitrary combinations of these two 75 01/07/13
- 76. Explorer: attribute selection DEMO
- 77. 77 University of Waikato 01/07/13
- 78. 78 University of Waikato 01/07/13
- 79. 79 University of Waikato 01/07/13
- 80. 80 University of Waikato 01/07/13
- 81. 81 University of Waikato 01/07/13
- 82. 82 University of Waikato 01/07/13
- 83. 83 University of Waikato 01/07/13
- 84. 84 University of Waikato 01/07/13
- 85. Explorer: data visualization Visualization very useful in practice: e.g. helps to determine difficulty of the learning problem WEKA can visualize single attributes (1-d) and pairs of attributes (2-d) To do: rotating 3-d visualizations (Xgobi-style) Color-coded class values “Jitter” option to deal with nominal attributes (and to detect “hidden” data points) “Zoom-in” function 85 01/07/13
- 86. data visualization DEMO
- 87. 87 University of Waikato 01/07/13
- 88. 88 University of Waikato 01/07/13
- 89. 89 University of Waikato 01/07/13
- 90. 90 University of Waikato 01/07/13
- 91. 91 University of Waikato 01/07/13
- 92. 92 University of Waikato 01/07/13
- 93. 93 University of Waikato 01/07/13
- 94. 94 University of Waikato 01/07/13
- 95. 95 University of Waikato 01/07/13
- 96. 96 University of Waikato 01/07/13
- 97. References and Resources References: WEKA website: http://www.cs.waikato.ac.nz/~ml/weka/index.html WEKA Tutorial: Machine Learning with WEKA: A presentation demonstrating all graphical user interfaces (GUI) in Weka. A presentation which explains how to use Weka for exploratory data mining. WEKA Data Mining Book: Ian H. Witten and Eibe Frank, Data Mining: Practical Machine Learning Tools and Techniques (Second Edition) WEKA Wiki: http://weka.sourceforge.net/wiki/index.php/Main_Page Others: Jiawei Han and Micheline Kamber, Data Mining: Concepts and Techniques, 2nd ed.