






























![[DataCon.TW 2017] Data Lake: centralize in on-prem vs. decentralize on cloud](https://cdn.slidesharecdn.com/ss_thumbnails/datalake-onprem-vs-oncloud-datacon-v3-20170930-171002041256-thumbnail.jpg?width=560&fit=bounds)






















Ad
More Related Content
What's hot (20)
Similar to WhereHows: Taming Metadata for 150K Datasets Over 9 Data Platforms (20)


















Ad
Recently uploaded (20)




















Ad
WhereHows: Taming Metadata for 150K Datasets Over 9 Data Platforms
- 1. Mars Lan The WhereHows Team Apr 26, 2017 Big Data Meetup @ LinkedIn WhereHows: Taming Metadata for 150K Datasets Over 9 Data Platforms Github: github.com/linkedin/WhereHows Gitter: gitter.im/wherehows Google Groups: WhereHows
- 2. ● LinkedIn’s Data Ecosystem ● The Metadata problem ● WhereHows: Architecture and Details ● Future Evolution Agenda
- 3. Mission Connect the world’s professionals to make them more productive and successful What is LinkedIn?
- 4. LinkedIn Data Ecosystem LinkedIn.com: Desktop, Mobile apps Services (Prod + Corp) Logs, Events, Messages Hadoop Streaming CDC Kafka Databases (Espresso, MySQL, Oracle) Samza Teradata Data standardization, Reporting, ML Data standardization, Reporting Derived Data Stores, Indexes (Pinot, Search, Voldemort, Venice, Graph, MySQL) Snapshots, incremental dumps ReadsReads, Writes Streaming Ingest Batch loads LinkedIn.corp: Internal applications (e.g. dashboards) Employees Members, Customers
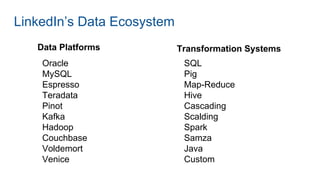
- 5. LinkedIn’s Data Ecosystem Oracle MySQL Espresso Teradata Pinot Kafka Hadoop Couchbase Voldemort Venice SQL Pig Map-Reduce Hive Cascading Scalding Spark Samza Java Custom Data Platforms Transformation Systems
- 6. ● Cross Platform ○ Silo-ed and non-interoperable metadata ○ Missing linkage between platforms ● Challenges within Platforms ○ Big data platforms (e.g. Hadoop) encourage sprawl ○ Schema-free systems => inferring structure is hard ○ Multiple processing frameworks => lineage tough Challenges Introduced by Diversity
- 8. WhereHows Open source @ github.com/linkedin/wherehows
- 9. WhereHows @ 10,000 ft
- 13. Lineage
- 15. WhereHows Concepts ● Dataset: A logical collection of data, e.g. Oracle table, Hive View, HDFS directory, Kafka topic ● Process / Flow: A processing workflow that contains one or more jobs ● Lineage: A relationship between datasets deduced from operation data ● Metric: A business metric with additional info on source, formula, dimensions, dashboard, wiki etc. ● Ownership: dev owner, producer, consumer, delegate, stakeholder
- 16. WhereHows Architecture WH MySQL WH App (Play + Ember) Metadata Store Rest.li API Catalog (Schema) HDFS, Teradata, Oracle, Kafka, Voldemort, Hive, ... Lineage Azkaban, Gobblin Ownership Git, ownership repository, ... Elastic Search Index Builder
- 17. Catalog - Challenges ● Standardization : Single metadata model that works with all platforms ○ Least-common-denominator vs leaky abstractions ○ What is a dataset? A Table? A Database? A Metric? ● Extraction : Each data platform stores metadata differently ○ HDFS - files/directories plus schema files ○ TD/Oracle - DBC.Table, ALL_TABLES etc ○ Kafka - Topic, Schema registry ● Freshness : Trust erodes with staleness Trust Freshness
- 18. Catalog - Our Approach ● URN-based naming for datasets in all platforms ○ Generalized + specialized metadata models under evolution ● Quick authoring of platform-specific ETL jobs using Jython ● Pull model (extract + transform) and push model (Kafka, REST) both exist
- 19. Lineage - Challenges ● Diversity in processing frameworks on Hadoop ● Inferring from code is not trivial - think UDF, external parameters etc ● Cross data platform lineage requires mapping all data copies ● Visualization is non-trivial with huge fan-out Pretty Understandable
- 20. Lineage - Our Approach ● Azkaban’s execution logs for intra-Hadoop lineage ○ Hadoop job ID => Job conf from job history node => source + destination pair ● AppWorx execution log ● Gobblin events for into-Hadoop and cross-Hadoop cluster lineage ● Heuristics based on known patterns ● Lineage API, Tabular representation for downstream impact We also have pretty, unreadable lineage graphs :)
- 21. Anatomy of Metadata ETL ● Extract ○ Gather metadata from source (direct query, crawling file system, log parsing etc) ○ Build JSON representation of metadata ○ Dump JSON to file ● Transform ○ Convert JSON objects into CSV conforming destination table structure ● Load ○ Load CSV files into table, performing diff if necessary Metadata DB Extract Transform LoadData Platform JSON CSV
- 22. Metadata Kafka Event (In Development) ● MetadataChangeEvent - Both delta & current snapshot of a dataset ● MetadataInventoryEvent - Periodic lightweight event for re-synchronization ● MetadataLineageEvent - For operation lineage Data platform WhereHowsKafkaMetadata Events Data processor
- 23. Active Work @ LinkedIn ● Product Experience ○ Improve search relevance ● Compliance: GDPR requirements ○ Fine-grained metadata acquisition across all data platforms ○ Purge specifications for datasets (actual deletion driven through Gobblin) ● Better Metadata ○ Column-level lineage using static analysis of Pig, Hive, Spark, Samza SQL, TD scripts ● Big Metadata ○ Support a wide range of storage backends for scale-out, specialized access patterns ■ Ground, Neo4j, LinkedIn’s GraphDB, NoSQL, REST services etc. ● Tech Improvement Items ○ Easier authoring/sharding/monitoring of metadata ETL using Gobblin
- 24. Feature Roadmap ● Product Experience ○ Better lineage visualization ○ Richer social collaboration ● Developer Happiness ○ Simplify build system & deployment ○ Admin API for ETL job management ○ Replace VM with Docker image
- 25. The Team Abhishek Agrawal Eng Mgr Tushar Shanbhag Product Nicole Li Project Mgr Wen Cui Design Eric Sun Mars Lan Na Zhang Yi Wang Seyi Adebajo Engineering
- 26. Thank You!