July 2025 - Top 10 Read Articles in Network Security & Its Applications.pdfIJNSA Journal
File Strucutres and Access in Data Structuresmwaslam2303
Basics of Auto Computer Aided Drafting .pptxKrunal Thanki
04 Origin of Evinnnnnnnnnnnnnnnnnnnnnnnnnnl-notes.pptLuckySangalala1
13th International Conference of Networks and Communications (NC 2025)JohannesPaulides
UNIT III CONTROL OF PARTICULATE CONTAMINANTSsundharamm
Natural Language processing and web deigning notesAnithaSakthivel3
Ad
word vector embeddings in natural languag processing
1. 1
Vector Embedding ofWords
A word is represented as a vector.
Word embeddings depend on a notion of word
similarity.
Similarity is computed using cosine.
A very useful definition is paradigmatic similarity:
Similar words occur in similar contexts. They are exchangeable.
POTUS
Yesterday The President called a press conference.
Trump
“POTUS: President of the United States.”
2. 2
Traditional Method - Bag ofWords Model
Either uses one hot encoding.
Each word in the vocabulary is represented
by one bit position in a HUGE vector.
For example, if we have a vocabulary of
10000 words, and “Hello” is the 4th word in
the dictionary, it would be represented by:
0 0 0 1 0 0 . . . . . . . 0 0 0
Or uses document representation.
Each word in the vocabulary is represented
by its presence in documents.
For example, if we have a corpus of 1M
documents, and “Hello” is in 1th, 3th and
5th documents only, it would be
represented by: 1 0 1 0 1 0 . . . . . . . 0 0 0
Context information is not utilized.
Word Embeddings
Stores each word in as a point in
space, where it is represented by a
dense vector of fixed number of
dimensions (generally 300) .
Unsupervised, built just by reading
huge corpus.
For example, “Hello” might be
represented as : [0.4, -0.11, 0.55, 0.3
. . . 0.1, 0.02].
Dimensions are basically
projections along different axes,
more of a mathematical concept.
Vector Embedding ofWords
3. 3
Example
vector[Queen] vector[King] - vector[Man] + vector[Woman]
vector[Paris] vector[France] - vector[ Italy] + vector[ Rome]
This can be interpreted as “France is to Paris as Italy is to Rome”.
4. 4
Working with vectors
Finding the most similar words to .
Compute the similarity from word to all other words.
This is a single matrix-vector product:
W is the word embedding matrix of |V| rows and d columns.
Result is a |V| sized vector of similarities.
Take the indices of the k-highest values.
5. 5
Working with vectors
Similarity to a group of words
“Find me words most similar to cat, dog and cow”.
Calculate the pairwise similarities and sum them:
Now find the indices of the highest values as before.
Matrix-vector products are wasteful. Better option:
6. 6
Applications ofWordVectors
Word Similarity
MachineTranslation
Part-of-Speech and Named Entity Recognition
Relation Extraction
Sentiment Analysis
Co-reference Resolution
Chaining entity mentions across multiple documents - can we find and unify the
multiple contexts in which mentions occurs?
Clustering
Words in the same class naturally occur in similar contexts, and this feature
vector can directly be used with any conventional clustering algorithms (K-
Means, agglomerative, etc). Human doesn’t have to waste time hand-picking
useful word features to cluster on.
Semantic Analysis of Documents
Build word distributions for various topics, etc.
7. 7
Vector Embedding ofWords
Three main methods described in the talk :
Latent Semantic Analysis/Indexing (1988)
Term weighting-based model
Consider occurrences of terms at document level.
Word2Vec (2013)
Prediction-based model.
Consider occurrences of terms at context level.
GloVe (2014)
Count-based model.
Consider occurrences of terms at context level.
ELMo (2018)
Language model-based.
A different embedding for each word for each task.
8. 8
Embedding: Latent Semantic Analysis
Latent semantic analysis studies documents in Bag-Of-
Words model (1988).
i.e. given a matrix A encoding some documents: is the count* of
word j in document i. Most entries are 0.
* Often tf-idf or other “squashing” functions of the count are used.
A
N docs
M words
10. 10
word2Vec: Local contexts
Instead of entire documents, Word2Vec uses
words k positions away from each center word.
These words are called context words.
Example for k=3:
“It was a bright cold day in April, and the clocks were
striking”.
Center word: red (also called focus word).
Context words: blue (also called target words).
Word2Vec considers all words as center words,
and all their context words.
11. 11
Word2Vec: Data generation (window size = 2)
Example: d1 = “king brave man” , d2 = “queen beautiful women”
word Word one hot
encoding
neighbor Neighbor one hot
encoding
king [1,0,0,0,0,0] brave [0,1,0,0,0,0]
king [1,0,0,0,0,0] man [0,0,1,0,0,0]
brave [0,1,0,0,0,0] king [1,0,0,0,0,0]
brave [0,1,0,0,0,0] man [0,0,1,0,0,0]
man [0,0,1,0,0,0] king [1,0,0,0,0,0]
man [0,0,1,0,0,0] brave [0,1,0,0,0,0]
queen [0,0,0,1,0,0] beautiful [0,0,0,0,1,0]
queen [0,0,0,1,0,0] women [0,0,0,0,0,1]
beautiful [0,0,0,0,1,0] queen [0,0,0,1,0,0]
beautiful [0,0,0,0,1,0] women [0,0,0,0,0,1]
woman [0,0,0,0,0,1] queen [0,0,0,1,0,0]
woman [0,0,0,0,0,1] beautiful [0,0,0,0,1,0]
12. 12
Word2Vec: Data generation (window size = 2)
Example: d1 = “king brave man” , d2 = “queen beautiful women”
word Word one hot
encoding
neighbor Neighbor one hot
encoding
king [1,0,0,0,0,0] brave [0,1,1,0,0,0]
man
brave [0,1,0,0,0,0] king [1,0,1,0,0,0]
man
man [0,0,1,0,0,0] king [1,1,0,0,0,0]
brave
queen [0,0,0,1,0,0] beautiful [0,0,0,0,1,1]
women
beautiful [0,0,0,0,1,0] queen [0,0,0,1,0,1]
women
woman [0,0,0,0,0,1] queen [0,0,0,1,1,0]
beautiful
13. 13
Continuous Bag ofWords
(CBOW)
Skip-Ngram
Word2Vec: main context representation models
Sum and
projection
W-2
W-1
w2
w0
w1
Input
Output
Projection
W-2
W-1
w2
w0
w1
Input
Output
Word2Vec is a predictive model.
Will focus on Skip-Ngram model
14. 14
How does word2Vec work?
Represent each word as a d dimensional vector.
Represent each context as a d dimensional
vector.
Initialize all vectors to random weights.
Arrange vectors in two matrices,W and C.
22. 22
Skip-Ngram:Training method
The prediction problem is modeled using soft-max:
Predict context words(s) c
From focus word w
Looks like logistic regression!
are features and the evidence is
The objective function (in log space):
23. 23
Skip-Ngram: Negative sampling
The objective function (in log space):
While the objective function can be computed optimized, it is
computationally expensive
is very expensive to compute due to the summation
Mikolov et al. proposed the negative-sampling
approach as a more efficient way of deriving word
embeddings:
24. 24
Skip-Ngram: Example
While more text:
Extract a word window:
Try setting the vector values such that:
is high!
Create a corrupt example by choosing a random word
Try setting the vector values such that:
is low!
25. 25
Skip-Ngram: How to select negative samples?
Can sample using frequency.
Problem: will sample a lot of stop-words.
Mikolov et al. proposed to sample using:
Not theoretically justified, but works well in practice!
26. 26
Relations Learned byWord2Vec
A relation is defined by the vector displacement in the first column. For each
start word in the other column, the closest displaced word is shown.
“Efficient Estimation of Word Representations in Vector Space” Tomas
Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean, Arxiv 2013
27. Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014.
GloVe: GlobalVectors forWord Representation.
GloVe: GlobalVectors forWord
Representation
28. 28
GloVe: GlobalVectors forWord Representation
While word2Vec is a predictive model — learning
vectors to improve the predictive ability, GloVe is
a count-based model.
Count-based models learn vectors by doing
dimensionality reduction on a co-occurrence
counts matrix.
Factorize this matrix to yield a lower-dimensional
matrix of words and features, where each row yields a
vector representation for each word.
The counts matrix is preprocessed by normalizing the
counts and log-smoothing them.
29. 29
GloVe:Training
The prediction problem is given by:
and are bias terms.
The objective function:
is a weighting function to penalize rare co-
occurrences.
30. 30
GloVe:Training
The model generates two sets of word vectors,
and .
and are equivalent and differ only as a result of
their random initializations.
The two sets of vectors should perform equivalently.
Authors proposed to use to get word vectors.
31. Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner,
Christopher Clark, Kenton Lee, Luke Zettlemoyer.
Deep contextualized word representations, 2018
ELMo: Embeddings from
Language Models
representations
Slides by Alex Olson
31
32. 32
Context is key
Language is complex, and context can
completely change the meaning of a word in a
sentence.
Example:
I let the kids outside to play.
He had never acted in a more famous play before.
It wasn’t a play the coach would approve of.
Need a model which captures the different
nuances of the meaning of words given the
surrounding text.
33. 33
Different senses for different tasks
Previous models (GloVe, Vord2Vec, etc.) only
have one representation per word
They can’t capture these ambiguities.
When you only have one representation, all
levels of meaning are combined.
Solution: have multiple levels of understanding.
ELMo: Embeddings from Language Model
representations
34. 34
What is language modelling?
Today’s goal: assign a probability to a sentence
MachineTranslation:
P(high winds tonight) > P(large winds tonight)
Spell Correction
The office is about fifteen minuets from my house!
P(about fifteen minutes from) > P(about fifteen minuets from)
Speech Recognition
P(I saw a van) >> P(eyes awe of an)
+ Summarization, question, answering, etc., etc.!!
Reminder:The Chain Rule
35. 35
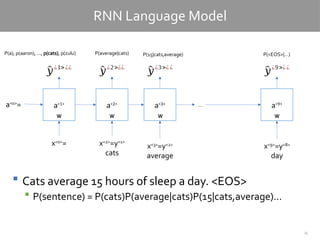
RNN Language Model
Cats average 15 hours of sleep a day. <EOS>
P(sentence) = P(cats)P(average|cats)P(15|cats,average)…
a<3>
a<2>
a<1>
a<9>
a<0>
=
x<0>
=
^
𝑦¿1>¿¿
P(a), p(aaron), …, p(cats), p(zulu)
^
𝑦¿2>¿¿
P(average|cats)
x<2>
=y<1>
cats
x<3>
=y<2>
average
^
𝑦¿3>¿ ¿
P(15|cats,average)
…
x<9>
=y<8>
day
^
𝑦¿9>¿ ¿
P(<EOS>|…)
W W W W
36. 36
Embeddings from Language Models
ELMo architecture trains a
language model using a 2-
layer bi-directional LSTM
(biLMs)
What input?
Traditional Neural Language
Models use fixed -length word
embedding.
One-hone encoding.
Word2Vec.
Glove.
Etc.…
ELMo uses a mode complex
representation.
37. 37
ELMo:What input?
Transformations applied for each
token before being provided to
input of first LSTM layer.
Pros of character embeddings:
It allows to pick up on morphological
features that word-level embeddings
could miss.
It ensures a valid representation
even for out-of-vocabulary words.
It allows us to pick up on n-gram
features that build more powerful
representations.
The highway network layers allow
for smoother information transfer
through the input.
38. 38
ELMo: Embeddings from Language Models
An example of combining the bidirectional hidden representations and word representation for
"happy" to get an ELMo-specific representation. Note: here we omit visually showing the complex
network for extracting the word representation that we described in the previous slide.
Intermediate representation
(output vector)
39. 39
ELMo mathematical details
The function f performs the following operation
on word k of the input:
Where represents softmax-normalized weights.
ELMo learns a separate
representation for each
task
Question answering,
sentiment analysis, etc.
40. 40
Difference to other methods
Nearest neighbors words to “play” using GloVe
and the nearest neighbor sentences to “play”
using ELMo.
Source Nearest Neighbors
GloVe play playing, game, games, played, players, plays,
player, Play, football, multiplayer
biLM
Chico Ruiz made a
spectacular play on
Alusik ’s grounder {. . . }
Kieffer , the only junior in the group , was
commended for his ability to hit in the clutch ,
as well as his all-round excellent play .
Olivia De Havilland
signed to do a Broadway
play for Garson {. . . }
{. . . } they were actors who had been handed
fat roles in a successful play , and had talent
enough to fill the roles competently , with nice
understatement .
41. 41
Bibliography
Mikolov, Tomas, et al. ”Efficient estimation of word representations in vector space.” arXiv
preprint arXiv:1301.3781 (2013).
Kottur, Satwik, et al. ”Visual Word2Vec (vis-w2v): Learning Visually Grounded Word
Embeddings Using Abstract Scenes.” arXiv preprint arXiv:1511.07067 (2015).
Lazaridou, Angeliki, Nghia The Pham, and Marco Baroni. ”Combining language and vision
with a multimodal skip-gram model.” arXiv preprint arXiv:1501.02598 (2015).
Rong, Xin. ”word2vec parameter learning explained.” arXiv preprint arXiv:1411.2738 (2014).
Mikolov, Tomas, et al. ”Distributed representations of words and phrases and their
compositionality.” Advances in neural information processing systems. 2013.
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global
Vectors forWord Representation.
Scott Deerwester et al. “Indexing by latent semantic analysis”. Journal of the American
society for information science (1990).
Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton
Lee, Luke Zettlemoyer.
Matt Gardner and Joel Grus and Mark Neumann and Oyvind Tafjord and Pradeep Dasigi and
Nelson F. Liu and Matthew Peters and Michael Schmitz and Luke S. Zettlemoyer. AllenNLP:
A Deep Semantic Natural Language Processing Platform.

![2
Traditional Method - Bag ofWords Model
Either uses one hot encoding.
Each word in the vocabulary is represented
by one bit position in a HUGE vector.
For example, if we have a vocabulary of
10000 words, and “Hello” is the 4th word in
the dictionary, it would be represented by:
0 0 0 1 0 0 . . . . . . . 0 0 0
Or uses document representation.
Each word in the vocabulary is represented
by its presence in documents.
For example, if we have a corpus of 1M
documents, and “Hello” is in 1th, 3th and
5th documents only, it would be
represented by: 1 0 1 0 1 0 . . . . . . . 0 0 0
Context information is not utilized.
Word Embeddings
Stores each word in as a point in
space, where it is represented by a
dense vector of fixed number of
dimensions (generally 300) .
Unsupervised, built just by reading
huge corpus.
For example, “Hello” might be
represented as : [0.4, -0.11, 0.55, 0.3
. . . 0.1, 0.02].
Dimensions are basically
projections along different axes,
more of a mathematical concept.
Vector Embedding ofWords](https://image.slidesharecdn.com/wordembed-250515201942-a984d0ff/85/word-vector-embeddings-in-natural-languag-processing-2-320.jpg)
![3
Example
vector[Queen] vector[King] - vector[Man] + vector[Woman]
vector[Paris] vector[France] - vector[ Italy] + vector[ Rome]
This can be interpreted as “France is to Paris as Italy is to Rome”.](https://image.slidesharecdn.com/wordembed-250515201942-a984d0ff/85/word-vector-embeddings-in-natural-languag-processing-3-320.jpg)







![11
Word2Vec: Data generation (window size = 2)
Example: d1 = “king brave man” , d2 = “queen beautiful women”
word Word one hot
encoding
neighbor Neighbor one hot
encoding
king [1,0,0,0,0,0] brave [0,1,0,0,0,0]
king [1,0,0,0,0,0] man [0,0,1,0,0,0]
brave [0,1,0,0,0,0] king [1,0,0,0,0,0]
brave [0,1,0,0,0,0] man [0,0,1,0,0,0]
man [0,0,1,0,0,0] king [1,0,0,0,0,0]
man [0,0,1,0,0,0] brave [0,1,0,0,0,0]
queen [0,0,0,1,0,0] beautiful [0,0,0,0,1,0]
queen [0,0,0,1,0,0] women [0,0,0,0,0,1]
beautiful [0,0,0,0,1,0] queen [0,0,0,1,0,0]
beautiful [0,0,0,0,1,0] women [0,0,0,0,0,1]
woman [0,0,0,0,0,1] queen [0,0,0,1,0,0]
woman [0,0,0,0,0,1] beautiful [0,0,0,0,1,0]](https://image.slidesharecdn.com/wordembed-250515201942-a984d0ff/85/word-vector-embeddings-in-natural-languag-processing-11-320.jpg)
![12
Word2Vec: Data generation (window size = 2)
Example: d1 = “king brave man” , d2 = “queen beautiful women”
word Word one hot
encoding
neighbor Neighbor one hot
encoding
king [1,0,0,0,0,0] brave [0,1,1,0,0,0]
man
brave [0,1,0,0,0,0] king [1,0,1,0,0,0]
man
man [0,0,1,0,0,0] king [1,1,0,0,0,0]
brave
queen [0,0,0,1,0,0] beautiful [0,0,0,0,1,1]
women
beautiful [0,0,0,0,1,0] queen [0,0,0,1,0,1]
women
woman [0,0,0,0,0,1] queen [0,0,0,1,1,0]
beautiful](https://image.slidesharecdn.com/wordembed-250515201942-a984d0ff/85/word-vector-embeddings-in-natural-languag-processing-12-320.jpg)