




























![w
ord2vec
vin . vout ∈ [-1,1]
objective
But the inner product ranges from -1 to 1 (when normalized)
…and we’d like a probability](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-30-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
vin . vout ∈ [-1,1]
objective
But the inner product ranges from -1 to 1 (when normalized)
…and we’d like a probability](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-31-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
softmax(vin . vout ∈ [-1,1])
objective
∈ [0,1]
Transform again using softmax](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-32-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
softmax(vin . vout ∈ [-1,1])
Probability of choosing 1 of N discrete items.
Mapping from vector space to a multinomial over words.
objective
Similar to logistic function for binary outcomes, but instead for 1 of N outcomes.
So now we’re modeling the probability of a word showing up as the combination of the training word vector and the target
word vector and transforming it to a 1 of N](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-33-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
exp(vin . vout ∈ [0,1])softmax ~
objective
So here’s the actual form of the equation — we normalize by the sum of all of the other possible pairs of word combinations](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-34-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
exp(vin . vout ∈ [-1,1])
Σexp(vin . vk)
softmax =
objective
Normalization term over all words
k ∈ V
So here’s the actual form of the equation — we normalize by the sum of all of the other possible pairs of word combinations
two effects
make vin and vout more similar
make vin and every other word less similar](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-35-320.jpg)
![w
ord2vec
But we’d like to measure a probability.
exp(vin . vout ∈ [-1,1])
Σexp(vin . vk)
softmax = = P(vout|vin)
objective
k ∈ V
This is the kernel of the word2vec. We’re just going to apply this operation every time we want to update the vectors.
For every word, we’re going to have a context window, and then for every pair of words in that window and the input word,
we’ll measure this probability.](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-36-320.jpg)




































![[ -0.75, -1.25, -0.55, -0.12, +2.2] [ 0%, 9%, 78%, 11%]
typical word2vec vector typical LDA document vector](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-73-320.jpg)
![typical word2vec vector
[ 0%, 9%, 78%, 11%]
typical LDA document vector
[ -0.75, -1.25, -0.55, -0.12, +2.2]
All sum to 100%All real values](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-74-320.jpg)
![5D word2vec vector
[ 0%, 9%, 78%, 11%]
5D LDA document vector
[ -0.75, -1.25, -0.55, -0.12, +2.2]
Sparse
All sum to 100%
Dimensions are absolute
Dense
All real values
Dimensions relative
LDA is a *mixture*
w2v is a bunch of real numbers — more like and *address*
much easier to say to another human 78% of something rather than it is +2.2 of something and -1.25 of something else](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-75-320.jpg)
![100D word2vec vector
[ 0%0%0%0%0% … 0%, 9%, 78%, 11%]
100D LDA document vector
[ -0.75, -1.25, -0.55, -0.27, -0.94, 0.44, 0.05, 0.31 … -0.12, +2.2]
Sparse
All sum to 100%
Dimensions are absolute
Dense
All real values
Dimensions relative
dense sparse](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-76-320.jpg)
![100D word2vec vector
[ 0%0%0%0%0% … 0%, 9%, 78%, 11%]
100D LDA document vector
[ -0.75, -1.25, -0.55, -0.27, -0.94, 0.44, 0.05, 0.31 … -0.12, +2.2]
Similar in fewer ways
(more interpretable)
Similar in 100D ways
(very flexible)
+mixture
+sparse](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-77-320.jpg)





















![lda2vec
Let’s make vDOC sparse
[ -0.75, -1.25, …]
vDOC = a vreligion + b vpolitics +…
Now 1st time I did this…
Hard to interpret. What does -1.2 politics mean? math works, but not intuitive](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-99-320.jpg)
































![from gensim.models import Doc2Vec
fn = “item_document_vectors”
model = Doc2Vec.load(fn)
model.most_similar('pregnant')
matches = list(filter(lambda x: 'SENT_' in x[0], matches))
# ['...I am currently 23 weeks pregnant...',
# '...I'm now 10 weeks pregnant...',
# '...not showing too much yet...',
# '...15 weeks now. Baby bump...',
# '...6 weeks post partum!...',
# '...12 weeks postpartum and am nursing...',
# '...I have my baby shower that...',
# '...am still breastfeeding...',
# '...I would love an outfit for a baby shower...']
sentence
search](https://image.slidesharecdn.com/datadaytalkwithpresenternotes-160116232231/85/word2vec-LDA-and-introducing-a-new-hybrid-algorithm-lda2vec-133-320.jpg)


























































More Related Content
What's hot (20)
Similar to word2vec, LDA, and introducing a new hybrid algorithm: lda2vec (20)


















Recently uploaded (20)




















word2vec, LDA, and introducing a new hybrid algorithm: lda2vec
- 1. A word is worth a thousand vectors (word2vec, lda, and introducing lda2vec) Christopher Moody @ Stitch Fix Welcome, thanks for coming, having me, organizer NLP can be a messy affair because you have to teach a computer about the irregularities and ambiguities of the English language in this sort of hierarchical sparse nature in all the grammar 3rd trimester, pregnant “wears scrubs” — medicine taking a trip — a fix for vacation clothing power of word vectors promise is to sweep away a lot of issues
- 2. About @chrisemoody Caltech Physics PhD. in astrostats supercomputing sklearn t-SNE contributor Data Labs at Stitch Fix github.com/cemoody Gaussian Processes t-SNE chainer deep learning Tensor Decomposition
- 3. Credit Large swathes of this talk are from previous presentations by: • Tomas Mikolov • David Blei • Christopher Olah • Radim Rehurek • Omer Levy & Yoav Goldberg • Richard Socher • Xin Rong • Tim Hopper
- 5. 1. king - man + woman = queen 2. Huge splash in NLP world 3. Learns from raw text 4. Pretty simple algorithm 5. Comes pretrained word2vec 1. Learns what words mean — can solve analogies cleanly. 1. Not treating words as blocks, but instead modeling relationships 2. Distributed representations form the basis of more complicated deep learning systems 3. Shallow — not deep learning! 1. Power comes from this simplicity — super fast, lots of data 4. Get a lot of mileage out of this 1. Don’t need to model the wikipedia corpus before starting your own
- 6. word2vec 1. Set up an objective function 2. Randomly initialize vectors 3. Do gradient descent
- 7. w ord2vec word2vec: learn word vector vin from it’s surrounding context vin 1. Let’s talk about training first 2. In SVD and n-grams we built a co-occurence and transition probability matrices 3. Here we will learn the embedded representation directly, with no intermediates, update it w/ every example
- 8. w ord2vec “The fox jumped over the lazy dog” Maximize the likelihood of seeing the words given the word over. P(the|over) P(fox|over) P(jumped|over) P(the|over) P(lazy|over) P(dog|over) …instead of maximizing the likelihood of co-occurrence counts. 1. Context — the words surrounding the training word 2. Naively assume P(*|over) is independent conditional on the training word 3. Still a pretty simple assumption! Conditioning on just *over* no other secret parameters or anything
- 10. w ord2vec P(vfox|vover) Should depend on the word vectors. P(fox|over) Trying to learn the word vectors, so let’s start with those (we’ll randomly initialize them to begin with)
- 11. w ord2vec Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word. “The fox jumped over the lazy dog” P(vOUT|vIN)
- 12. w ord2vec “The fox jumped over the lazy dog” vIN P(vOUT|vIN) Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word. IN = training word
- 13. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word.
- 14. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word.
- 15. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word.
- 16. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word.
- 17. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word.
- 18. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word.
- 19. w ord2vec P(vOUT|vIN) “The fox jumped over the lazy dog” vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word.
- 20. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word. …So that at a high level is what we want word2vec to do.
- 21. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word. …So that at a high level is what we want word2vec to do.
- 22. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word. …So that at a high level is what we want word2vec to do.
- 23. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word. …So that at a high level is what we want word2vec to do.
- 24. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word. …So that at a high level is what we want word2vec to do.
- 25. w ord2vec “The fox jumped over the lazy dog” vOUT P(vOUT|vIN) vIN Twist: we have two vectors for every word. Should depend on whether it’s the input or the output. Also a context window around every input word. …So that at a high level is what we want word2vec to do. two for loops That’s it! A bit disengious to make this a giant network
- 26. objective Measure loss between vIN and vOUT? vin . vout How should we define P(vOUT|vIN)? Now we’ve defined the high-level update path for the algorithm. Need to define this prob exactly in order to define our updates. Boils down to diff between in & out — want to make as similar as possible, and then the probability will go up. Use cosine sim.
- 27. w ord2vec vin . vout ~ 1 objective vin vout Dot product has these properties: Similar vectors have similarly near 1
- 28. w ord2vec objective vin vout vin . vout ~ 0 Orthogonal vectors have similarity near 0
- 29. w ord2vec objective vin vout vin . vout ~ -1 Orthogonal vectors have similarity near -1
- 30. w ord2vec vin . vout ∈ [-1,1] objective But the inner product ranges from -1 to 1 (when normalized) …and we’d like a probability
- 31. w ord2vec But we’d like to measure a probability. vin . vout ∈ [-1,1] objective But the inner product ranges from -1 to 1 (when normalized) …and we’d like a probability
- 32. w ord2vec But we’d like to measure a probability. softmax(vin . vout ∈ [-1,1]) objective ∈ [0,1] Transform again using softmax
- 33. w ord2vec But we’d like to measure a probability. softmax(vin . vout ∈ [-1,1]) Probability of choosing 1 of N discrete items. Mapping from vector space to a multinomial over words. objective Similar to logistic function for binary outcomes, but instead for 1 of N outcomes. So now we’re modeling the probability of a word showing up as the combination of the training word vector and the target word vector and transforming it to a 1 of N
- 34. w ord2vec But we’d like to measure a probability. exp(vin . vout ∈ [0,1])softmax ~ objective So here’s the actual form of the equation — we normalize by the sum of all of the other possible pairs of word combinations
- 35. w ord2vec But we’d like to measure a probability. exp(vin . vout ∈ [-1,1]) Σexp(vin . vk) softmax = objective Normalization term over all words k ∈ V So here’s the actual form of the equation — we normalize by the sum of all of the other possible pairs of word combinations two effects make vin and vout more similar make vin and every other word less similar
- 36. w ord2vec But we’d like to measure a probability. exp(vin . vout ∈ [-1,1]) Σexp(vin . vk) softmax = = P(vout|vin) objective k ∈ V This is the kernel of the word2vec. We’re just going to apply this operation every time we want to update the vectors. For every word, we’re going to have a context window, and then for every pair of words in that window and the input word, we’ll measure this probability.
- 37. w ord2vec Learn by gradient descent on the softmax prob. For every example we see update vin vin := vin + P(vout|vin) objective vout := vout + P(vout|vin) …I won’t go through the derivation of the gradient, but this is the general idea relatively simple, fast — fast enough to read billions of words in a day
- 39. word2vec if not convinced by qualitative results….
- 41. Showing just 2 of the ~500 dimensions. Effectively we’ve PCA’d it
- 52. If we only had locality and not regularity, this wouldn’t necessarily be true
- 55. So we live in a vector space where operations like addition and subtraction are meaningful. So here’s a few examples of this working. Really get the idea of these vectors as being ‘mixes’ of other ideas & vectors
- 56. ITEM_3469 + ‘Pregnant’ SF is a person service Box
- 57. + ‘Pregnant’ I love the stripes and the cut around my neckline was amazing someone else might write ‘grey and black’ subtlety and nuance in that language We have lots of this interaction — of order wikipedia amount — far too much to manually annotate anything
- 58. = ITEM_701333 = ITEM_901004 = ITEM_800456
- 59. Stripes and are safe for maternity And also similar tones and flowy — still great for expecting mothers
- 60. what about?LDA?
- 61. LDA on Client Item Descriptions This shows the incredible amount of structure
- 62. LDA on Item Descriptions (with Jay) clunky jewelry dangling delicate jewelry elsewhere
- 63. LDA on Item Descriptions (with Jay) topics on patterns, styles — this cluster is similarly described as high contrast tops with popping colors
- 64. LDA on Item Descriptions (with Jay) bright dresses for a warm summer
- 65. LDA on Item Descriptions (with Jay) maternity line clothes
- 66. LDA on Item Descriptions (with Jay) not just visual topics, but also topics about fit
- 67. Latent style vectors from text Pairwise gamma correlation from style ratings Diversity from ratings Diversity from text Lots of structure in both — but the diversity much higher in the text Maybe obvious: but the way people describe items is fundamentally richer than the style ratings
- 68. lda vs word2vec
- 69. word2vec is local: one word predicts a nearby word “I love finding new designer brands for jeans” as if the world where one very long text string. no end of documents, no end of sentence, etc. and a window across words
- 70. “I love finding new designer brands for jeans” But text is usually organized. as if the world where one very long text string. no end of documents, no end of sentence, etc.
- 71. “I love finding new designer brands for jeans” But text is usually organized. as if the world where one very long text string. no end of documents, no end of sentence, etc.
- 72. “I love finding new designer brands for jeans” In LDA, documents globally predict words. doc 7681 these are client comment which are short, only predict dozens of words but could be legal documents, or medical documents, 10k words — here the difference between global and local algorithms is much more important
- 73. [ -0.75, -1.25, -0.55, -0.12, +2.2] [ 0%, 9%, 78%, 11%] typical word2vec vector typical LDA document vector
- 74. typical word2vec vector [ 0%, 9%, 78%, 11%] typical LDA document vector [ -0.75, -1.25, -0.55, -0.12, +2.2] All sum to 100%All real values
- 75. 5D word2vec vector [ 0%, 9%, 78%, 11%] 5D LDA document vector [ -0.75, -1.25, -0.55, -0.12, +2.2] Sparse All sum to 100% Dimensions are absolute Dense All real values Dimensions relative LDA is a *mixture* w2v is a bunch of real numbers — more like and *address* much easier to say to another human 78% of something rather than it is +2.2 of something and -1.25 of something else
- 76. 100D word2vec vector [ 0%0%0%0%0% … 0%, 9%, 78%, 11%] 100D LDA document vector [ -0.75, -1.25, -0.55, -0.27, -0.94, 0.44, 0.05, 0.31 … -0.12, +2.2] Sparse All sum to 100% Dimensions are absolute Dense All real values Dimensions relative dense sparse
- 77. 100D word2vec vector [ 0%0%0%0%0% … 0%, 9%, 78%, 11%] 100D LDA document vector [ -0.75, -1.25, -0.55, -0.27, -0.94, 0.44, 0.05, 0.31 … -0.12, +2.2] Similar in fewer ways (more interpretable) Similar in 100D ways (very flexible) +mixture +sparse
- 78. can we do both? lda2vec series of exp grain of salt very new — no good quantitative results only qualitative (but promising!)
- 79. The goal: Use all of this context to learn interpretable topics. P(vOUT |vIN)word2vec @chrisemoody Use this at SF. typical table w2v will use w-w
- 80. word2vec LDA P(vOUT |vDOC) The goal: Use all of this context to learn interpretable topics. this document is 80% high fashion this document is 60% style @chrisemoody LDA will use that doc ID column you can use this to steer the business as a whole
- 81. word2vec LDA The goal: Use all of this context to learn interpretable topics. this zip code is 80% hot climate this zip code is 60% outdoors wear @chrisemoody But doesn’t predict word-to-word relationships. in texas, maybe i want more lonestars & stirrup icons in austin, maybe i want more bats
- 82. word2vec LDA The goal: Use all of this context to learn interpretable topics. this client is 80% sporty this client is 60% casual wear @chrisemoody love to learn client topics are there ‘types’ of clients? q every biz asks so this is the promise of lda2vec
- 83. lda2vec word2vec predicts locally: one word predicts a nearby word P(vOUT |vIN) vIN vOUT “PS! Thank you for such an awesome top” But doesn’t predict word-to-word relationships.
- 84. lda2vec LDA predicts a word from a global context doc_id=1846 P(vOUT |vDOC) vOUT vDOC “PS! Thank you for such an awesome top” But doesn’t predict word-to-word relationships.
- 85. lda2vec doc_id=1846 vIN vOUT vDOC can we predict a word both locally and globally ? “PS! Thank you for such an awesome top”
- 86. lda2vec “PS! Thank you for such an awesome top”doc_id=1846 vIN vOUT vDOC can we predict a word both locally and globally ? P(vOUT |vIN+ vDOC) doc vector captures long-distance dependencies word vector captures short-distance
- 87. lda2vec doc_id=1846 vIN vOUT vDOC *very similar to the Paragraph Vectors / doc2vec can we predict a word both locally and globally ? “PS! Thank you for such an awesome top” P(vOUT |vIN+ vDOC)
- 88. lda2vec This works! 😀 But vDOC isn’t as interpretable as the LDA topic vectors. 😔 Too many documents. I really like that document X is 70% in topic 0, 30% in topic1, …
- 89. lda2vec This works! 😀 But vDOC isn’t as interpretable as the LDA topic vectors. 😔 Too many documents. I really like that document X is 70% in topic 0, 30% in topic1, … about as interpretable a hash
- 90. lda2vec This works! 😀 But vDOC isn’t as interpretable as the LDA topic vectors. 😔 Too many documents. I really like that document X is 70% in topic 0, 30% in topic1, …
- 91. lda2vec This works! 😀 But vDOC isn’t as interpretable as the LDA topic vectors. 😔 We’re missing mixtures & sparsity. Too many documents. I really like that document X is 70% in topic 0, 30% in topic1, …
- 92. lda2vec This works! 😀 But vDOC isn’t as interpretable as the LDA topic vectors. 😔 Let’s make vDOC into a mixture… Too many documents. I really like that document X is 70% in topic 0, 30% in topic1, …
- 93. lda2vec Let’s make vDOC into a mixture… vDOC = a vtopic1 + b vtopic2 +… (up to k topics) sum of other word vectors intuition here is that ‘hanoi = vietnam + capital’ and lufthansa = ‘germany + airlines’ so we think that document vectors should also be some word vector + some word vector
- 94. lda2vec Let’s make vDOC into a mixture… vDOC = a vtopic1 + b vtopic2 +… Trinitarian baptismal Pentecostals Bede schismatics excommunication twenty newsgroup dataset, free, canonical
- 95. lda2vec Let’s make vDOC into a mixture… vDOC = a vtopic1 + b vtopic2 +… topic 1 = “religion” Trinitarian baptismal Pentecostals Bede schismatics excommunication
- 96. lda2vec Let’s make vDOC into a mixture… vDOC = a vtopic1 + b vtopic2 +… Milosevic absentee Indonesia Lebanese Isrealis Karadzic topic 1 = “religion” Trinitarian baptismal Pentecostals Bede schismatics excommunication
- 97. lda2vec Let’s make vDOC into a mixture… vDOC = a vtopic1 + b vtopic2 +… topic 1 = “religion” Trinitarian baptismal Pentecostals bede schismatics excommunication topic 2 = “politics” Milosevic absentee Indonesia Lebanese Isrealis Karadzic purple a,b coefficients tell you how much it is that topic
- 98. lda2vec Let’s make vDOC into a mixture… vDOC = 10% religion + 89% politics +… topic 2 = “politics” Milosevic absentee Indonesia Lebanese Isrealis Karadzic topic 1 = “religion” Trinitarian baptismal Pentecostals bede schismatics excommunication Doc is now 10% religion 89% politics mixture models are powerful for interpretability
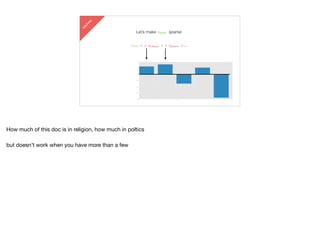
- 99. lda2vec Let’s make vDOC sparse [ -0.75, -1.25, …] vDOC = a vreligion + b vpolitics +… Now 1st time I did this… Hard to interpret. What does -1.2 politics mean? math works, but not intuitive
- 100. lda2vec Let’s make vDOC sparse vDOC = a vreligion + b vpolitics +… How much of this doc is in religion, how much in poltics but doesn’t work when you have more than a few
- 101. lda2vec Let’s make vDOC sparse vDOC = a vreligion + b vpolitics +… How much of this doc is in religion, how much in cars but doesn’t work when you have more than a few
- 102. lda2vec Let’s make vDOC sparse {a, b, c…} ~ dirichlet(alpha) vDOC = a vreligion + b vpolitics +… trick we can steal from bayesian make it dirichlet skipping technical details make everything sum to 100% penalize non-zero force model to only make it non-zero w/ lots of evidence
- 103. lda2vec Let’s make vDOC sparse {a, b, c…} ~ dirichlet(alpha) vDOC = a vreligion + b vpolitics +… sparsity-inducing effect. similar to the lasso or l1 reg, but dirichlet few dimensions, sum to 100% I can say to the CEO, set of docs could have been in 100 topics, but we picked only the best topics
- 104. word2vec LDA P(vOUT |vIN + vDOC)lda2vec The goal: Use all of this context to learn interpretable topics. @chrisemoody this document is 80% high fashion this document is 60% style go back to our problem lda2vec is going to use all the info here
- 105. word2vec LDA P(vOUT |vIN+ vDOC + vZIP)lda2vec The goal: Use all of this context to learn interpretable topics. @chrisemoody add column = adding a term add features in an ML model
- 106. word2vec LDA P(vOUT |vIN+ vDOC + vZIP)lda2vec The goal: Use all of this context to learn interpretable topics. this zip code is 80% hot climate this zip code is 60% outdoors wear @chrisemoody in addition to doc topics, like ‘rec SF’
- 107. word2vec LDA P(vOUT |vIN+ vDOC + vZIP +vCLIENTS)lda2vec The goal: Use all of this context to learn interpretable topics. this client is 80% sporty this client is 60% casual wear @chrisemoody client topics — sporty, casual, this is where if she says ‘3rd trimester’ — identify a future mother ‘scrubs’ — medicine
- 108. word2vec LDA P(vOUT |vIN+ vDOC + vZIP +vCLIENTS) P(sold | vCLIENTS) lda2vec The goal: Use all of this context to learn interpretable topics. @chrisemoody Can also make the topics supervised so that they predict an outcome. helps fine-tune topics so that correlate with your favorite business metric align topics w/ expectations helps us guess when revenue goes up what the leading causes are
- 109. github.com/cemoody/lda2vec uses pyldavis API Ref docs (no narrative docs) GPU Decent test coverage @chrisemoody
- 110. “PS! Thank you for such an awesome idea” @chrisemoody doc_id=1846 Can we model topics to sentences? lda2lstm SF is all about mixing cutting edge algorithms but we absolutely need interpretability. human component to algos is not negotiable Could we demand the model make us a sentence that is 80% religion, 10% politics? classify word level, LSTM on sentence, LDA on document level
- 111. “PS! Thank you for such an awesome idea” @chrisemoody doc_id=1846 Can we represent the internal LSTM states as a dirichlet mixture? Dirichlet-squeeze internal states and manipulations, that maybe will help us understand the science of LSTM dynamics — because seriously WTF is going on there
- 112. Can we model topics to sentences? lda2lstm “PS! Thank you for such an awesome idea”doc_id=1846 @chrisemoody Can we model topics to images? lda2ae TJ Torres Can we also extend this to image generation? TJ is working on a ridiculous VAE/GAN model… can we throw in a topic model? Can we say make me an image that is 80% sweater, and 10% zippers, and 10% elbow patches?
- 116. Bonus slides
- 119. Crazy Approaches Paragraph Vectors (Just extend the context window) Content dependency (Change the window grammatically) Social word2vec (deepwalk) (Sentence is a walk on the graph) Spotify (Sentence is a playlist of song_ids) Stitch Fix (Sentence is a shipment of five items)
- 120. See previous
- 121. CBOW “The fox jumped over the lazy dog” Guess the word given the context ~20x faster. (this is the alternative.) vOUT vIN vINvIN vIN vIN vIN SkipGram “The fox jumped over the lazy dog” vOUT vOUT vIN vOUT vOUT vOUTvOUT Guess the context given the word Better at syntax. (this is the one we went over) CBOW sums words vectors, loses the order in the sentence Both are good at semantic relationships Child and kid are nearby Or gender in man, woman If you blur words over the scale of context — 5ish words, you lose a lot grammatical nuance But skipgram preserves order Preserves the relationship in pluralizing, for example
- 122. Shows that are many words similar to vacation actually come in lots of flavors — wedding words (bachelorette, rehearsals) — holiday/event words (birthdays, brunch, christmas, thanksgiving) — seasonal words (spring, summer,) — trip words (getaway) — destinations
- 123. LDA Results context H istory I loved every choice in this fix!! Great job! Great Stylist Perfect
- 124. LDA Results context H istory Body Fit My measurements are 36-28-32. If that helps. I like wearing some clothing that is fitted. Very hard for me to find pants that fit right.
- 125. LDA Results context H istory Sizing Really enjoyed the experience and the pieces, sizing for tops was too big. Looking forward to my next box! Excited for next
- 126. LDA Results context H istory Almost Bought It was a great fix. Loved the two items I kept and the three I sent back were close! Perfect
- 127. What I didn’t mention A lot of text (only if you have a specialized vocabulary) Cleaning the text Memory & performance Traditional databases aren’t well-suited False positives hundreds of millions of words, 1,000 books, 500,000 comments, or 4,000,000 tweets high-memory and high-performance multicore machine. Training can take several hours to several days but shouldn't need frequent retraining. If you use pretrained vectors, then this isn't an issue. Databases. Modern SQL systems aren't well-suited to performing the vector addition, subtraction and multiplication searching in vector space requires. There are a few libraries that will help you quickly find the most similar items12: annoy, ball trees, locality-sensitive hashing (LSH) or FLANN. False-positives & exactness. Despite the impressive results that come with word vectorization, no NLP technique is perfect. Take care that your system is robust to results that a computer deems relevant but an expert human wouldn't.
- 128. and now for something completely crazy
- 129. All of the following ideas will change what ‘words’ and ‘context’ represent. But we’ll still use the same w2v algo
- 130. paragraph vector What about summarizing documents? On the day he took office, President Obama reached out to America’s enemies, offering in his first inaugural address to extend a hand if you are willing to unclench your fist. More than six years later, he has arrived at a moment of truth in testing that
- 131. On the day he took office, President Obama reached out to America’s enemies, offering in his first inaugural address to extend a hand if you are willing to unclench your fist. More than six years later, he has arrived at a moment of truth in testing that The framework nuclear agreement he reached with Iran on Thursday did not provide the definitive answer to whether Mr. Obama’s audacious gamble will pay off. The fist Iran has shaken at the so-called Great Satan since 1979 has not completely relaxed. paragraph vector Normal skipgram extends C words before, and C words after. IN OUT OUT Except we stay inside a sentence
- 132. On the day he took office, President Obama reached out to America’s enemies, offering in his first inaugural address to extend a hand if you are willing to unclench your fist. More than six years later, he has arrived at a moment of truth in testing that The framework nuclear agreement he reached with Iran on Thursday did not provide the definitive answer to whether Mr. Obama’s audacious gamble will pay off. The fist Iran has shaken at the so-called Great Satan since 1979 has not completely relaxed. paragraph vector A document vector simply extends the context to the whole document. IN OUT OUT OUT OUTdoc_1347
- 134. translation (using just a rotation matrix) M ikolov 2013 English Spanish Matrix Rotation Blows my mind Explain plot Not a complicated NN here Still have to learn the rotation matrix — but it generalizes very nicely. Have analogies for every linalg op as a linguistic operator: + and - and matrix multiplies Robust framework and new tools to do science on words
- 135. context dependent Levy & G oldberg 2014 Australian scientist discovers star with telescope context +/- 2 words
- 136. context dependent context Australian scientist discovers star with telescope Levy & G oldberg 2014 What if we
- 137. context dependent context Australian scientist discovers star with telescope context Levy & G oldberg 2014
- 138. context dependent context BoW DEPS topically-similar vs ‘functionally’ similar Levy & G oldberg 2014
- 139. context dependent context Levy & G oldberg 2014 Also show that SGNS is simply factorizing: w * c = PMI(w, c) - log k This is completely amazing! Intuition: positive associations (canada, snow) stronger in humans than negative associations (what is the opposite of Canada?) Also means we can do SVD-like techniques to get a convex w2v, uses fast lining libs, uses compressed word count matrix so also better storage…. but not online
- 140. deepwalk Perozzi etal2014 learn word vectors from sentences “The fox jumped over the lazy dog” vOUT vOUT vOUT vOUT vOUTvOUT ‘words’ are graph vertices ‘sentences’ are random walks on the graph word2vec
- 141. Playlists at Spotify context sequence learning ‘words’ are songs ‘sentences’ are playlists
- 142. Playlists at Spotify context Erik Bernhardsson Great performance on ‘related artists’
- 143. Fixes at Stitch Fix sequence learning Let’s try: ‘words’ are styles ‘sentences’ are fixes
- 144. Fixes at Stitch Fix context Learn similarity between styles because they co-occur Learn ‘coherent’ styles sequence learning
- 145. Fixes at Stitch Fix? context sequence learning Got lots of structure!
- 147. Fixes at Stitch Fix? context sequence learning Nearby regions are consistent ‘closets’
- 150. A specific lda2vec model Our text blob is a comment that comes from a region_id and a style_id
- 159. Can measure similarity between topic vectors m and n, and word vectors w This gets you the ‘top’ words in a topic, can figure out what that topic is
- 161. lda2vec Let’s make vDOC into a mixture… vDOC = 10% religion + 89% politics +… topic 2 = “politics” Milosevic absentee Indonesia Lebanese Isrealis Karadzic topic 1 = “religion” Trinitarian baptismal Pentecostals bede schismatics excommunication This is now on the 20 newsgroups dataset… Doc is now 10% religion 89% politics mixture models are powerful for interpretability