



















































![[Mark’s Slides]](https://image.slidesharecdn.com/xsede2014-scigap-tutorial-140725121754-phpapp01/85/XSEDE14-SciGaP-Apache-Airavata-Tutorial-53-320.jpg)













![Anatomy of the PHP Command Lines
• Imports of Thrift Libraries
– require_once $GLOBALS['THRIFT_ROOT'] .
'Transport/TTransport.php';
– An so on
• Make sure the path to the libraries
(‘THRIFT_ROOT’) is correct.
• The libs are generated from the IDL.](https://image.slidesharecdn.com/xsede2014-scigap-tutorial-140725121754-phpapp01/85/XSEDE14-SciGaP-Apache-Airavata-Tutorial-68-320.jpg)
![Importing Airavata Libraries
• Import of Airavata API
– require_once $GLOBALS['AIRAVATA_ROOT'] .
'API/Airavata.php';
• Import data models
– require_once $GLOBALS['AIRAVATA_ROOT'] .
'Model/Workspace/Types.php';
– require_once $GLOBALS['AIRAVATA_ROOT'] .
'Model/Workspace/Experiment/Types.php’;
• These are 1-1 mappings from the our Thrift API
definition files.](https://image.slidesharecdn.com/xsede2014-scigap-tutorial-140725121754-phpapp01/85/XSEDE14-SciGaP-Apache-Airavata-Tutorial-69-320.jpg)



















![XSEDE Science Gateways
Program Overview
Quick overview, plus cookbook
[I think this must go into
supplemental material]](https://image.slidesharecdn.com/xsede2014-scigap-tutorial-140725121754-phpapp01/85/XSEDE14-SciGaP-Apache-Airavata-Tutorial-89-320.jpg)







































Ad
More Related Content
What's hot (20)
Viewers also liked (6)




Ad
Similar to XSEDE14 SciGaP-Apache Airavata Tutorial (20)




















Ad
More from marpierc (14)














Recently uploaded (20)








![Get & Download Wondershare Filmora Crack Latest [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/revolutionizingresidentialwi-fi-250422112639-60fb726f-250429170801-59e1b240-thumbnail.jpg?width=560&fit=bounds)






![Download Wondershare Filmora Crack [2025] With Latest](https://cdn.slidesharecdn.com/ss_thumbnails/neo4j-howkgsareshapingthefutureofgenerativeaiatawssummitlondonapril2024-240426125209-2d9db05d-250419-250428115407-a04afffa-thumbnail.jpg?width=560&fit=bounds)




XSEDE14 SciGaP-Apache Airavata Tutorial
- 1. SciGaP Tutorial: Developing Science Gateways using Apache Airavata XSEDE14, July 14th 2014, Atlanta GA
- 3. More Information • Contact Us: – [email protected], [email protected] – Join [email protected], [email protected], [email protected] • Websites: – SciGaP Project: http://scigap.org – Apache Airavata: http://airavata.apache.org – Science Gateway Institute: http://sciencegateways.org
- 4. Audience Introductions Tell us about your work or studies and your reasons for taking the tutorial Sign in and take survey
- 5. Role Description Gateway Developers and Providers Use the Airavata API through and SDK in their favorite programming language. Airavata Developers Want to change Airavata components, experiment with different implementations. Middleware Developers Want to extend Airavata to talk to their middleware clients. Resource Providers Want to configure Airavata to work with their middleware.
- 6. What You Will Learn • What a Science Gateway is and does. • How to build a simple Science Gateway. • How to integrate existing gateways with XSEDE and other resources • What it takes to run a production gateway.
- 8. What You Can Take Away • A “test-drive” PHP gateway – Open source code in GitHub – We’ll run SciGaP services for you • OR: Gateway client SDKs for your programming language of choice – Integrate with your gateway – We’ll run SciGaP services for you • OR: Airavata source code – Play, use, or develop and contribute back
- 9. Example Science Gateways UltraScan, CIPRES, and Neuroscience Gateways
- 10. A Science Gateway for Biophysical Analysis Usage statistics (in SUs) for the UltraScan Gateway Jan-Dec 2013 There are over 70 institutions in 18 countries actively using UltraScan/LIMS Implemented currently on 7 HPC platforms, including one commercial installation (non-public). In 2013 over 1.5 Million service units provided by XSEDE, Jülich and UTHSCSA. Ongoing Projects: Integration of SAXS/SANS modeling Integration of Molecular Dynamics (DMD) Integration of SDSC Gordon Supercomputer with GRAM5 and UNICORE Integration of Multi-wavelength optics (500-1000 fold higher data density) Development of Performance Prediction algorithms through datamining Development of a meta scheduler for mass submissions (of MW data)
- 11. UltraScan Goals: Provide highest possible resolution in the analysis – requires HPC Offer a flexible approach for multiple optimization methods Integrate a variety of HPC environments into a uniform submission framework (Campus resources, XSEDE, International resources) Must be easy to learn and use – users should not have to be HPC experts Support a large number of users and analysis instances simultaneously Support data sharing and collaborations Easy installation, easy maintenance Robust and secure multi-user/multi-role framework Provide check-pointing and easy to understand error messages Fast turnaround to support serial workflows (model refinement) A Science Gateway for Biophysical Analysis
- 12. Demo of the UltraScan Gateway
- 13. Browser UltraScan Gateway (UTHSCSA) Airavata Services (Quarry VM Hosting) Apache Thrift API Server Apache Thrift Client SDK Campus Resources Middleware Plugins Trestles (XSEDE) Stampede (XSEDE) Juelich HTTPS TCP/IP GRAM, GSI-SSH UNICORE, JSDL, BES
- 14. UltraScan and Gateway Patterns • Users create computational packages (experiments) – Data to be analyzed, analysis parameters and control files. – Computing resources to use and computing parameters (# of processors, wall time, memory, etc) • Experiments are used to launch jobs. • Running jobs are monitored • User may access intermediate details • Results from completed jobs (including failures) need to be moved to permanent data management system
- 15. UltraScan and Gateway Patterns, Continued • UltraScan users are not just XSEDE users. • UltraScan provides access to campus and international resources as well as XSEDE. • Gateways are user-centric federating layers over grids, clouds, and no-middleware solutions
- 16. PHP Gateway for Airavata (PGA) Demo of and hands on with the Test Drive Portal http://test-drive.airavata.org/ PGA is a GTA
- 17. Application Field Scenario AMBER Molecular Dynamics Production constant pressure and temperature (NPT) MD run of alanine dipeptide. Trinity Bioinformatics RNA-Seq De novo Assembly GROMACS Molecular Dynamics Minimize the energy of a protein from the PDB. LAMMPS Molecular Dynamics Atomistic simulation of friction. NWChem Ab Initio Quantum Chemistry Optimized geometry and vibrational frequencies of a water molecule. Quantum Espresso Ab Initio Quantum Chemistry Self-consistent field calculations (that is, approximate many-body wave function) for aluminum. WRF Mesoscale Weather Forecasting US East Coast storm from 2000. See https://github.com/SciGaP/XSEDE-Job-Scripts/ for more information
- 19. Browser PHP Gateway (gw120) PHP Command Line Tools (gw104) Airavata API Server (gw111) Airavata Components Resource 1 (Trestles) Resource 2 (Stampede) Resource 3 (Big Red II) (…) HTTPS TCP/IP (Thrift) TCP/IP (Thrift) Moving parts in the test-drive. Identity Server (gw26) HTTPS SSH, GSI-SSH
- 20. Portal Hands On Time Run all the applications
- 21. Getting the Demo Portal Code • Demo Portal is available from GitHub – Note: this may be moved to the Airavata Git Repo – Look for announcements on the Airavata mailing lists • Go to https://github.com/SciGaP/PHP-Reference- Gateway – Create a clone • Contribute back with pull requests and patches!
- 22. A Tour of the API Examining PHP Clients
- 23. Client Objects for Job Submission Experiment Inputs (DataObject) User Configuration Computational Resource Experiment Advanced Output Handling
- 24. How to Create an Experiment • Go to GitHub – http://s.apache.org/php-clients • Download the Airavata PHP client zip. – https://dist.apache.org/repos/dist/dev/airavata/0.13/ RC0/apache-airavata-php-sdk-0.13-SNAPSHOT- bin.tar.gz – Look at createExperiment.php – We also have C++ • If you prefer, we have training accounts on gw104 – Need SSH to access
- 25. More API Usage PHP Sample What it shows launchExperiment.php How to run an experiment. getExperimentStatus.php How to check the status. getExperimentOutput.php How to get the outputs.
- 26. Hands On with PHP Command- Line Clients Exercises with the clients. Use the tar on your local machine or else log into gw104
- 28. Behind the API • The Airavata API server deposits Experiment information in the Registry. • API calls Orchestrator to validate and launch jobs. • Orchestrator schedules the job, uses GFAC to connect with a specific resource. • Multiple resources across administrative domains – Campus, XSEDE, etc – This requires different access mechanisms
- 30. A Few Observations on Successful Gateways • Support familiar community applications. • Make HPC systems easy for new user communities who need HPC. • Have champions who build and support the community. • Have a lot of common features.
- 31. SciGaP Goals: Improve sustainability by converging on a single set of hosted infrastructure services
- 32. Understanding the Airavata API, Part 1 Creating, executing, and managing experiments.
- 35. Airavata API and Apache Thrift • We use Apache Thrift to define the API. • Advantages of Thrift – Supports well-defined, typed messages. – Custom defined errors, exceptions – Generators for many different programming languages. – Some shielding from API versioning problems. • Downsides of Thrift – No message headers in TCP/IP, so everything must be explicitly defined in the API. – Limits on object-oriented features (polymorphism)
- 36. More Information • ApacheCon 2014 Presentation: “RESTLess Design with Apache Thrift: Experiences from Apache Airavata” • http://www.slideshare.net/smarru/restless- design-with-apache-thrift-experiances
- 37. Understanding the Airavata API, Part 2 Managing applications, computing resources, and gateway profiles
- 38. Application Catalog Summary • The Application Catalog includes descriptions of computing resources and applications. – It is part of the Registry. • Call the API to add, delete, or modify a resource or an application. • The App Catalog API and data models are in transition to Thrift. – You can also still use legacy methods, which fully featured.
- 39. App Catalog Model Compute Resource Model Application Interface Model Application Deployment Model Gateway Profile Moedel
- 40. Data Model Description Compute Resource Everything you need to know about a particular computing resource. Application Interface Resource independent information about an application. Application Deployment Compute Resource-specific information about an application. Gateway Resource Profile Gateway-specific preferences for a given computing resource.
- 41. Using the Application Catalog API Walk through how to create, modify applications and computing resources Live examples with {lammps, gromacs, espresso,…} on {stampede, trestles, br2} http://s.apache.org/register-apps
- 42. Application Catalog Details Back to http://airavata.apache.org/document ation/api-docs/0.13/
- 43. Airavata Under the Hood More detail about how Airavata works
- 44. Airavata’s Philosophy • There a lots of ways to build Web interfaces for Science Gateways. – By Hand: PHP, Twitter Bootstrap, AngularJS, … – Turnkey Frameworks: Drupal, Plone, Joomla, … – Science Gateway Frameworks: the SDSC Workbench, HUBzero, WS-PGrade • Gateway developers should concentrate on building interfaces that serve their community. • And outsource the general purpose services to Airavata.
- 45. Apache Airavata Components Component Description Airavata API Server Thrift-generated server skeletons of the API and data models; directs traffic to appropriate components Registry Insert and access application, host machine, workflow, and provenance data. Orchestrator Handles experiment execution request validation, scheduling, and decision making; selects GFAC instances that can fulfill a given request Application Factory Service (GFAC) Manages the execution and monitoring of an individual application. Workflow Interpreter Service Execute the workflow on one or more resources. Messaging System WS-Notification and WS-Eventing compliant publish/subscribe messaging system for workflow events
- 47. Getting Help Help Description Airavata Developer List Get in touch with Airavata developers. Good place for asking general questions. Lots of automated traffic noise. See apache.airavata.org/community/mailing-lists.html. Mailing list is public and archived online. Airavata Jira Official place for posting bugs, tasks, etc. Posts here also go to the developer mailing list. See https://issues.apache.org/jira/browse/airavata Airavata users, architects lists Can also post here. Use “users” list for questions. The architects’ list is for higher level design discussions. Airavata Wiki and Website The Wiki is frequently updated but also may have obsolete material. The Website should have time-independent documentation. What else would you like to see? Google Hangouts, IRCs, YouTube, social networks? Improvements to the Website?
- 48. Airavata and SciGaP • SciGaP: Airavata as part of a multi-tenanted Gateway Platform as a Service • Goal: We run Airavata so you don’t have to. • Challenges: – Centralize system state – Make Airavata more cloud friendly, elastic
- 49. “Apache” Means “Open” Join the Airavata developer mailing list, get involved, submit patches, contribute. Use Give Back
- 50. Getting Involved, Contributing Back • Airavata is open source, open community software. • Open Community: you can contribute back – Patches, suggestions, wiki documentation, etc • We reward contributors – Committers: write access to master Git repo – Project Management Committee members: full, binding voting rights
- 51. Some Contribution Opportunities Component Research Opportunities Registry Better support for Thrift-generated objects; NoSQL and other backend data stores; fault tolerance Orchestrator Pluggable scheduling; load balancing and elasticity GFAC ZooKeeper-like strategies for configuring and managing. Messenger Investigate AMQP, Kafka, and other newer messaging systems Workflow Interpreter Alternative workflow processing engines. Overall Message-based rather than direct CPI calls. Airavata components (should) expose Component Programming Interfaces (CPIs) that allow you to switch out implementations. GFAC is also designed to be pluggable.
- 52. Advice on running a gateway Experiences with CIPRES
- 53. [Mark’s Slides]
- 54. Wrap Up What to Do Next
- 55. Building on the Tutorial Material • Test-drive gateway will remain up. • Go over the PHP samples. • Get other code examples – JAVA, C++, Python, … • Contact the Airavata developer list for help.
- 56. Get Involved in Apache Airavata • Join the architecture mailing list. • Join the developer list. • All contributions welcome. – Apache Software Foundation owns the IP. – Submit patches and earn committership, PMC membership.
- 57. Where Is Airavata 1.0? • Airavata 1.0 will be the stable version of the API. • Developer community vote. – Get involved – September 2014 target • Semantic versioning
- 58. Get Connected, Get Help • Get Connected: Join the XSEDE Science Gateway program community mailing list. – Email [email protected] – “subscribe gateways” • Get Help: Get XSEDE extended collaborative support for your gateway. • Get Info: https://www.xsede.org/gateways- overview
- 59. More Information • Contact Us: – [email protected], [email protected] – Join – [email protected] – [email protected], [email protected], • Websites: – SciGaP Project: http://scigap.org – Apache Airavata: http://airavata.apache.org – Science Gateway Institute: http://sciencegateways.org
- 60. Backup Slides Here they are
- 61. Using Airavata Directly Slides on how to run your own Airavata services
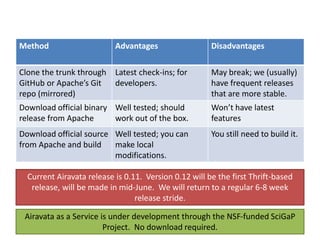
- 62. Downloading Airavata Method Advantages Disadvantages Clone the trunk through GitHub or Apache’s Git repo (mirrored) Latest check-ins; for developers. May break; we (usually) have frequent releases that are more stable. Download official binary release from Apache Well tested; should work out of the box. Won’t have latest features Download official source from Apache and build Well tested; you can make local modifications. You still need to build it. Current Airavata release is 0.11. Version 0.12 will be the first Thrift-based release, will be made in mid-June. We will return to a regular 6-8 week release stride. Airavata as a Service is under development through the NSF-funded SciGaP Project. No download required.
- 63. Building Airavata from Source • You need Apache Maven. • Use “mvn clean install” • Would you like to see other packaging? –Pre-configured VMs? –PaaS tools like OpenShift, Apache Stratos? –Docker?
- 64. Running Airavata • Modify airavata-server.properties (optional) – airavata/modules/distribution/server/target/apac he-airavata-server-{version}/bin/ if building from source. – Typically required to specify the XSEDE community credential. • Start the server using airavata-server.sh. – Same location as airavata-server.properties
- 65. Generating Client SDKs with Thrift
- 66. Generating New Thrift Clients • airavata/airavata-api/generate-thrift- files.sh • Shows how to do this for Java, C++, and PHP • Caveat: requires Thrift installation • See airavata/airavata-api/thrift-interface- descriptions/ for our Thrift definitions
- 67. Writing a PHP Interface to the Airavata API This is a set of slides that summarizes what you need to do to call the API from PHP.
- 68. Anatomy of the PHP Command Lines • Imports of Thrift Libraries – require_once $GLOBALS['THRIFT_ROOT'] . 'Transport/TTransport.php'; – An so on • Make sure the path to the libraries (‘THRIFT_ROOT’) is correct. • The libs are generated from the IDL.
- 69. Importing Airavata Libraries • Import of Airavata API – require_once $GLOBALS['AIRAVATA_ROOT'] . 'API/Airavata.php'; • Import data models – require_once $GLOBALS['AIRAVATA_ROOT'] . 'Model/Workspace/Types.php'; – require_once $GLOBALS['AIRAVATA_ROOT'] . 'Model/Workspace/Experiment/Types.php’; • These are 1-1 mappings from the our Thrift API definition files.
- 70. Initialize the AiravataClient • AiravataClient has all the API functions. • You can configure the client manually or through the AiravataClientFactory object. – The examples do this manually • We use Binary protocol and TSocket for wire protocol and transport • We recommend giving the client a long timeout (5 seconds or more).
- 71. Make the API Calls • $airavataclient = new AiravataClient($protocol); • $project=$airavataclient->getProject(‘user1’) • And so on. • Put these in try/catch blocks and catch Airavata exceptions. • Thrift exceptions will also be thrown. • $transport->close() when done
- 73. Plan: Ask the Experts • We are collaborating with Von Welch’s Center for Trustworthy Cyberinfrastructure (CTSC) – Von, Jim Basney, Randy Heiland • This is an ongoing review • Open issues are – Thrift over TCP/IP or Thrift over HTTPS? – Verifying user identity, gateway identity, and user roles. • Airavata architecture mailing lists
- 74. AuthN, AuthZ, and the Client API • Airavata assumes a trust relationship with gateways. – Best practice: use SSL, mutual authentication. – Firewall rules: clients come from known IPs. • The gateway makes AuthN and AuthZ decisions about its users. • Airavata trusts the gateway’s assertions • For command line examples, you are the gateway, not the user
- 75. Auth{Z,N} Problems and Solutions • Client-Airavata security is turned off for demo • The approach does not scale. – Clients may not have well-known IP addresses (Desktop clients for example). – Airavata service operators serving multiple gateways have to manually configure • Not self-service • We are evaluating a developer key scheme. – Modeled after Evernote client SDKs
- 76. More on Airavata Security • “A Credential Store for Multi-tenant Science Gateways”, Kanewala, Thejaka Amilia; Marru, Suresh; Basney, Jim; Pierce, Marlon – Proceedings of CCGrid 2014 (this conference!) • http://hdl.handle.net/2022/17379
- 78. Airavata and Middleware • Airavata’s philosophy is that gateways need ad-hoc access to all kinds of resources that are not centrally managed. – Grids, clouds, campus clusters • These resources are accessed through many different mechanisms. – SSH, JSDL/BES, HTCondor, Globus, … • These resources may also run job management systems – PBS, SLURM – Workflow engines – Parameter sweep tools – Hadoop and related tools • So we’ll describe how to extend Airavata’s GFAC
- 79. GFAC Plugins: Providers and Handlers • Providers: clients to common middleware. – Airavata comes with SSH, Globus GRAM, BES/JSDL, “localhost”, EC2 and other providers. • Handlers: customize providers for specific resources. – Set-up, stage-in, stage-out, and tear-down operations. • A given GFAC invocation involves 1 Provider and 0 or more Handlers. • Gfac-core invokes Handlers in sequence before (“in- handlers”) and after (“out-handlers”) the provider.
- 80. A Simple Example • Let’s write two handlers and a localhost provider. • Prerequisite: you have Airavata installed • InHandler: emails user • Provider: runs “echo” via local execution • OutHandler: emails user
- 81. Configure the InHandler • Place this in gfac-config.xml. • Note gfac-core lets you provide arbitrary properties. <Handler class="org.apache.airavata.gfac.local.handler.InputEmailHandler "> <property name="username" value="gmail- [email protected]"/> <property name="password" value="gmail-password-xxx"/> <property name="mail.smtp.auth” value="true"/> <property name="mail.smtp.starttls.enable" value="true"/> <property name="mail.smtp.host” value="smtp.gmail.com"/> <property name="mail.smtp.port" value="587"/> </Handler>
- 82. Configure the OutHandler These are read by the following code. initProperties is a GFacHandler interface method. <Handler class="org.apache.airavata.gfac.local.handler.OutputEmailHandler"> <property name="username" value="[email protected]"/> <property name="password" value="gmail-password-xxx"/> <property name="mail.smtp.auth” value="true"/> <property name="mail.smtp.starttls.enable" value="true"/> <property name="mail.smtp.host” value="smtp.gmail.com"/> <property name="mail.smtp.port" value="587"/> </Handler> private Properties props; public void initProperties(Properties properties) throws GFacHandlerException { props = properties; }
- 83. Write InputEmailHandler public void invoke(JobExecutionContext jec) throws GFacHandlerException { Map<String, Object> parameters = jec.getInMessageContext().getParameters(); StringBuffer buffer = new StringBuffer(); for (String input : parameters.keySet()) { ActualParameter inParam = (ActualParameter) parameters.get(input); String paramDataType = inParam.getType().getType().toString(); if ("String".equals(paramDataType)) { String stringPrm = ((StringParameterType) inParam.getType()).getValue(); buffer.append("Input Name:” + input + ”Input Value: “ +stringPrm + "n"); } } message.setText(buffer.toString()); } Bold font indicates Airavata-specific code.
- 84. Write the Output Handler • In our example, it is nearly identical.
- 85. Write a “Localhost” Provider • This runs a command on the same machine as the GFAC instance. • We already have one in Airavata’s code base.
- 86. gfac-config.xml <Provider class="org.apache.airavata.gfac.local.provider.impl.LocalProvider" host="org.apache.airavata.schemas.gfac.impl.HostDescriptionTypeImpl”> <InHandlers> <Handler class="org.apache.airavata.gfac.local.handler.LocalDirectorySetupHandler"/> <Handler class="org.apache.airavata.gfac.local.handler.InputEmailHandler"> <!– Parameters shown in previous example --> </Handler> </InHandlers> <OutHandlers> <Handler class="org.apache.airavata.gfac.local.handler.OutputEmailHandler"> <!– Parameters shown in previous example </Handler> </OutHandlers> </Provider>
- 87. More Information • Contact Us: – [email protected], [email protected] – Join [email protected], [email protected], [email protected] • Websites: – Apache Airavata: http://airavata.apache.org – SciGaP Project: http://scigap.org – Science Gateway Institute: http://sciencegateways.org
- 88. Quick Thanks to Devs and Testers • Eroma Abeysinghe • Lahiru Gunathilake • Yu Ma • Raminder Singh • Saminda Wijeratne • Chathuri Wimalasena • Sachith Withana • Some may join via Google Hangout
- 89. XSEDE Science Gateways Program Overview Quick overview, plus cookbook [I think this must go into supplemental material]
- 90. Why Airavata? Why SciGaP
- 91. Why Use Airavata for Gateways • Open community, not just open source. – Become a stakeholder, have a say. • Gateway-centric overlay federation. – Not tied to specific infrastructure. • No additional middleware required. – Campus clusters – Let your sysadmins know • Stable funding • Lots of room for distributed computing research – Pluggable services
- 92. Why Use SciGaP? • Outsource common services, concentrate on community building. • Use same services as UltraScan, CIPRES, NSG • Open deployments. – No secrets about how we run services • Lots of eyes on the services.
- 93. Upcoming Stuff Things on the way for Airavata, SciGaP
- 94. What’s On the Way? • Airavata 1.0 targeted for September – 0.13, 0.14 will follow in the next 2 months. • OpenStack service hosting – Rackspace has donated $2000/month usage. • API production usage by UltraScan – Have been using Airavata for last 9 months • CIPRES integration – NSG has some advanced requirements • Continued improvement to PGA Portal – Java, Python, and other GTAs welcome • More fun with Identity Server and API • Desktop SDKs
- 95. What is Analytical Ultracentrifugation (AUC)? A technique to separate macromolecules dissolved in solution in a centrifugal force field. AUC can “watch” the molecules while they are separating and identify and differentiate them by their hydrodynamic properties and partial concentration. AUC is a “first Principle” method, which does NOT require standards. How does AUC work? By applying a very large centrifugal force, molecules are separated based on their molar mass and their shape. The molecules are observed using different optical systems that detect different properties of the molecules, such as refractive index, UV or visible absorbance, or fluorescent light emission. What molecules can be studied? Virtually any molecule, colloid or particle that can be dissolved in a liquid can be measured by AUC, as long as it does not sediment by gravity alone. The molecule or particle can be as small as a salt ion, or as large as an entire virus particle. The ultracentrifuge can spin at 60,000 rpm, generating forces close to 300,000 x g. Even small molecules like salt ions will sediment in such a force. AUC Background
- 96. Simplified access to phylogenetics codes on powerful XSEDE resources The CIPRES Gateway has allowed 8600+ users to access 45.7 million core hours of XSEDE time for 260,000 jobs, resulting in 700+ publications.
- 97. Easy user interface – providing easy model upload, running of codes Complete set of neuronal simulation tools – NEURON, GENESIS, Brian, NEST, PyNN – widely used by computational neuroscientists Ability to easily get to the results, download results Democratize computational neuroscience The NSG is a simple and secure online science portal that provides access to computational neuroscience codes on XSEDE HPC resources http://www.nsgportal.org Amit Majumdar (PI), Maryann Martone (Co-PI), Subha Sivagnanm (Sr. Personnel) Kenneth Yoshimoto (Sr. Personnel), Anita Bandrowski (Sr. Personnel), Vadim Astakhov UCSD Ted Carnevale (PI), Yale School of Medicine NSF Awards: ABI #1146949; ABI #1146830
- 98. The UltraScan science gateway supports high performance computing analysis of biophysics experiments using XSEDE, Juelich, and campus clusters. Desktop analysis tools are integrated with the Web portal. Launch analysis and monitor through a browser We can help you build gateways for your lab or facility.