You only look once: Unified, real-time object detection (UPC Reading Group)
Download as PPTX, PDF15 likes10,835 views

Slides from the UPC reading group on computer vision about the following paper: Redmon, Joseph, Santosh Divvala, Ross Girshick, and Ali Farhadi. "You only look once: Unified, real-time object detection." arXiv preprint arXiv:1506.02640 (2015).
1 of 21
Downloaded 875 times
![YOLO:
You Only Look Once
Unified Real-Time Object Detection
Slides by: Andrea Ferri
For: Computer Vision Reading Group (08/03/16)
Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi
[Website] [Paper] [arXiv] [Reviews]](https://image.slidesharecdn.com/05yoloxthesisslides-160316122611/85/You-only-look-once-Unified-real-time-object-detection-UPC-Reading-Group-1-320.jpg)



















Ad
Recommended
[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=560&fit=bounds)
[PR12] You Only Look Once (YOLO): Unified Real-Time Object DetectionTaegyun Jeon The document summarizes the You Only Look Once (YOLO) object detection method. YOLO frames object detection as a single regression problem to directly predict bounding boxes and class probabilities from full images in one pass. This allows for extremely fast detection speeds of 45 frames per second. YOLO uses a feedforward convolutional neural network to apply a single neural network to the full image. This allows it to leverage contextual information and makes predictions about bounding boxes and class probabilities for all classes with one network.
Yolov3
Yolov3SHREY MOHAN Yolo is an end-to-end, real-time object detection system that uses a single convolutional neural network to predict bounding boxes and class probabilities directly from full images. It uses a deeper Darknet-53 backbone network and multi-scale predictions to achieve state-of-the-art accuracy while running faster than other algorithms. Yolo is trained on a merged ImageNet and COCO dataset and predicts bounding boxes using predefined anchor boxes and associated class probabilities at three different scales to localize and classify objects in images with just one pass through the network.
Machine Learning - Convolutional Neural Network
Machine Learning - Convolutional Neural NetworkRichard Kuo The document provides an overview of convolutional neural networks (CNNs) for visual recognition. It discusses the basic concepts of CNNs such as convolutional layers, activation functions, pooling layers, and network architectures. Examples of classic CNN architectures like LeNet-5 and AlexNet are presented. Modern architectures such as Inception and ResNet are also discussed. Code examples for image classification using TensorFlow, Keras, and Fastai are provided.
You only look once (YOLO) : unified real time object detection
You only look once (YOLO) : unified real time object detectionEntrepreneur / Startup YOLO (You Only Look Once) is a real-time object detection system that frames object detection as a regression problem. It uses a single neural network that predicts bounding boxes and class probabilities directly from full images in one evaluation. This approach allows YOLO to process images and perform object detection over 45 frames per second while maintaining high accuracy compared to previous systems. YOLO was trained on natural images from PASCAL VOC and can generalize to new domains like artwork without significant degradation in performance, unlike other methods that struggle with domain shift.
Yolo
YoloNEHA Kapoor In Comparison with other object detection algorithms, YOLO proposes the use of an end-to-end neural network that makes predictions of bounding boxes and class probabilities all at once.
You only look once
You only look onceGin Kyeng Lee 1. YOLO proposes a unified object detection model that predicts bounding boxes and class probabilities in one pass of a neural network.
2. It divides the image into a grid and has each grid cell predict B bounding boxes, confidence scores for each box, and C class probabilities.
3. This output is encoded as a tensor and the model is trained end-to-end using a mean squared error between the predicted and true output tensors to optimize localization accuracy and class prediction.
Yolo
YoloBang Tsui Liou (1) YOLO frames object detection as a single regression problem to predict bounding boxes and class probabilities directly from full images in one step. (2) It resizes images as input to a convolutional network that outputs a grid of predictions with bounding box coordinates, confidence, and class probabilities. (3) YOLO achieves real-time speeds while maintaining high average precision compared to other detection systems, with most errors coming from inaccurate localization rather than predicting background or other classes.
You Only Look Once: Unified, Real-Time Object Detection
You Only Look Once: Unified, Real-Time Object DetectionDADAJONJURAKUZIEV YOLO, a new approach to object detection. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation.
Deep learning for object detection
Deep learning for object detectionWenjing Chen This document discusses and compares different methods for deep learning object detection, including region proposal-based methods like R-CNN, Fast R-CNN, Faster R-CNN, and Mask R-CNN as well as single shot methods like YOLO, YOLOv2, and SSD. Region proposal-based methods tend to have higher accuracy but are slower, while single shot methods are faster but less accurate. Newer methods like Faster R-CNN, R-FCN, YOLOv2, and SSD have improved speed and accuracy over earlier approaches.
PR-207: YOLOv3: An Incremental Improvement
PR-207: YOLOv3: An Incremental ImprovementJinwon Lee YOLOv3 makes the following incremental improvements over previous versions of YOLO:
1. It predicts bounding boxes at three different scales to detect objects more accurately at a variety of sizes.
2. It uses Darknet-53 as its feature extractor, which provides better performance than ResNet while being faster to evaluate.
3. It predicts more bounding boxes overall (over 10,000) to detect objects more precisely, as compared to YOLOv2 which predicts around 800 boxes.
Anatomy of YOLO - v1
Anatomy of YOLO - v1Jihoon Song This document provides an overview of the YOLO object detection system. YOLO frames object detection as a single regression problem to predict bounding boxes and class probabilities in one step. It divides the image into a grid where each cell predicts bounding boxes and conditional class probabilities. YOLO is very fast, processing images in real-time. However, it struggles with small objects and localization accuracy compared to methods like Fast R-CNN that have a region proposal step. Combining YOLO with Fast R-CNN can improve performance by leveraging their individual strengths.
Object detection and Instance Segmentation
Object detection and Instance SegmentationHichem Felouat The document discusses object detection and instance segmentation models like YOLOv5, Faster R-CNN, EfficientDet, Mask R-CNN, and TensorFlow's object detection API. It provides information on labeling images with bounding boxes for training these models, including open-source and commercial annotation tools. The document also covers evaluating object detection models using metrics like mean average precision (mAP) and intersection over union (IoU). It includes an example of training YOLOv5 on a custom dataset.
A Brief History of Object Detection / Tommi Kerola
A Brief History of Object Detection / Tommi KerolaPreferred Networks Object detection is an important computer vision technique with applications in several domains such as autonomous driving, personal and industrial robotics. The below slides cover the history of object detection from before deep learning until recent research. The slides aim to cover the history and future directions of object detection, as well as some guidelines for how to choose which type of object detector to use for your own project.
Yolo
YoloSourav Garai This document discusses the real-time object detection method YOLO (You Only Look Once). YOLO divides an image into grids and predicts bounding boxes and class probabilities for each grid cell. It sees the full image at once rather than using a sliding window approach. This allows it to detect objects in one pass of the neural network, making it very fast compared to other methods. YOLO is also accurate, achieving a high mean average precision. However, it can struggle to precisely localize small objects and objects that appear in dense groups.
YOLOv4: optimal speed and accuracy of object detection review
YOLOv4: optimal speed and accuracy of object detection reviewLEE HOSEONG YOLOv4 builds upon previous YOLO models and introduces techniques like CSPDarknet53, SPP, PAN, Mosaic data augmentation, and modifications to existing methods to achieve state-of-the-art object detection speed and accuracy while being trainable on a single GPU. Experiments show that combining these techniques through a "bag of freebies" and "bag of specials" approach improves classifier and detector performance over baselines on standard datasets. The paper contributes an efficient object detection model suitable for production use with limited resources.
Object Detection using Deep Neural Networks
Object Detection using Deep Neural NetworksUsman Qayyum Recent Talk at PI school covering following contents
Object Detection
Recent Architecture of Deep NN for Object Detection
Object Detection on Embedded Computers (or for edge computing)
SqueezeNet for embedded computing
TinySSD (object detection for edge computing)
Introduction to object detection
Introduction to object detectionBrodmann17 This is part 1/4 of Brodmann17 A-Z Deep Learning based Object Detection meetup given by Assaf Mushinsky
Object detection
Object detectionSomesh Vyas Object detection using opencv for detecting objects. Flow chart, Algorithm and implementation are explained.
Yolov5 
Yolov5 Hochschule Bonn-Rhein-Sieg The document describes the architecture of 4 YOLOv5 object detection models of different sizes - small, medium, large, and extra large. Each model uses the same basic building blocks of focus, convolutional, and bottleneck CSP layers followed by upsampling and concatenation, but with different input channel sizes and numbers of layers to process images of different resolutions.
Yolo releases gianmaria
Yolo releases gianmariaDeep Learning Italia YOLO releases are one-stage object detection models that predict bounding boxes and class probabilities in an image using a single neural network. YOLO v1 divides the image into a grid and predicts bounding boxes and confidence scores for each grid cell. YOLO v2 improves on v1 with anchor boxes, batch normalization, and a Darknet-19 backbone network. YOLO v3 uses a Darknet-53 backbone, multi-scale feature maps, and a logistic classifier to achieve better accuracy. The YOLO models aim to perform real-time object detection with high accuracy while remaining fast and unified end-to-end models.
PR-132: SSD: Single Shot MultiBox Detector
PR-132: SSD: Single Shot MultiBox DetectorJinwon Lee SSD is a single-shot object detector that processes the entire image at once, rather than proposing regions of interest. It uses a base VGG16 network with additional convolutional layers to predict bounding boxes and class probabilities at three scales simultaneously. SSD achieves state-of-the-art accuracy while running significantly faster than two-stage detectors like Faster R-CNN. It introduces techniques like default boxes, hard negative mining, and data augmentation to address class imbalance and improve results on small objects. On PASCAL VOC 2007, SSD detects objects at 59 FPS with 74.3% mAP, comparable to Faster R-CNN but much faster.
Object detection with deep learning
Object detection with deep learningSushant Shrivastava This document discusses object detection using the Single Shot Detector (SSD) algorithm with the MobileNet V1 architecture. It begins with an introduction to object detection and a literature review of common techniques. It then describes the basic architecture of convolutional neural networks and how they are used for feature extraction in SSD. The SSD framework uses multi-scale feature maps for detection and convolutional predictors. MobileNet V1 reduces model size and complexity through depthwise separable convolutions. This allows SSD with MobileNet V1 to perform real-time object detection with reduced parameters and computations compared to other models.
SSD: Single Shot MultiBox Detector (UPC Reading Group)
SSD: Single Shot MultiBox Detector (UPC Reading Group)Universitat Politècnica de Catalunya Slides by Míriam Bellver at the UPC Reading group for the paper:
Liu, Wei, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, and Scott Reed. "SSD: Single Shot MultiBox Detector." ECCV 2016.
Full listing of papers at:
https://github.com/imatge-upc/readcv/blob/master/README.md
Deep learning based object detection basics
Deep learning based object detection basicsBrodmann17 The document discusses different approaches to object detection in images using deep learning. It begins with describing detection as classification, where an image is classified into categories for what objects are present. It then discusses approaches that involve separating detection into a classification head and localization head. The document also covers improvements like R-CNN which uses region proposals to first generate candidate object regions before running classification and bounding box regression on those regions using CNN features. This helps address issues with previous approaches like being too slow when running the CNN over the entire image at multiple locations and scales.
Real-time object detection coz YOLO!
Real-time object detection coz YOLO!J On The Beach Real-time object detection coz YOLO! by Shagufta Gurmukhdas
You Only Look Once is a state-of-the-art, high speed real-time object detection algorithm. It looks at the whole image at test time so its predictions are informed by global context in the image. This talk teaches you to develop your own application to detect and classify objects in images & videos.
1.Intro to YOLO algorithm
2. Image detection on video with YOLO
3. Processing images in Python, adding bounding boxes and labels
4. Processing complete videos in Python in the similar way as the previous section
5. Processing real time video from webcam
Object detection
Object detectionROUSHAN RAJ KUMAR Object detection is a computer technology related to computer vision and image processing that deals with detecting instances of semantic objects of a certain class (such as humans, buildings, or cars) in digital images and videos. Well-researched domains of object detection include face detection and pedestrian detection. Object detection has applications in many areas of computer vision, including image retrieval and video surveillance.
Yolo v2 ai_tech_20190421
Yolo v2 ai_tech_20190421穗碧 陳 YOLO v2 improves upon YOLO v1 in three main ways:
1. It is better by adding techniques like batch normalization, multi-scale training, and anchor boxes to improve accuracy.
2. It is faster by using a smaller input size of 416x416.
3. It is stronger by directly predicting bounding boxes rather than offsets, adding fine-grained features, and using dimensional clustering to select anchor boxes.
YOLO
YOLOgeothomas18 This document discusses the YOLO object detection algorithm and its applications in real-time object detection. YOLO frames object detection as a regression problem to predict bounding boxes and class probabilities in one pass. It can process images at 30 FPS. The document compares YOLO versions 1-3 and their improvements in small object detection, resolution, and generalization. It describes implementing YOLO with OpenCV and its use in self-driving cars due to its speed and contextual awareness.
object-detection.pptx
object-detection.pptxMohamedAliHabib3 This document provides an overview of object detection using convolutional neural networks (CNNs). It discusses why CNNs are well-suited for object detection, defines object detection, and describes several popular CNN-based object detection algorithms including R-CNN, Fast R-CNN, Faster R-CNN, and YOLO. It also covers important object detection concepts like region proposals, sliding windows, IoU for evaluating localization accuracy, and NMS for removing overlapping detections. Open-source resources for implementing these algorithms are also provided.
Faster R-CNN: Towards real-time object detection with region proposal network...
Faster R-CNN: Towards real-time object detection with region proposal network...Universitat Politècnica de Catalunya Slides by Amaia Salvador at the UPC Computer Vision Reading Group.
Source document on GDocs with clickable links:
https://docs.google.com/presentation/d/1jDTyKTNfZBfMl8OHANZJaYxsXTqGCHMVeMeBe5o1EL0/edit?usp=sharing
Based on the original work:
Ren, Shaoqing, Kaiming He, Ross Girshick, and Jian Sun. "Faster R-CNN: Towards real-time object detection with region proposal networks." In Advances in Neural Information Processing Systems, pp. 91-99. 2015.
Ad
More Related Content
What's hot (20)
Deep learning for object detection
Deep learning for object detectionWenjing Chen This document discusses and compares different methods for deep learning object detection, including region proposal-based methods like R-CNN, Fast R-CNN, Faster R-CNN, and Mask R-CNN as well as single shot methods like YOLO, YOLOv2, and SSD. Region proposal-based methods tend to have higher accuracy but are slower, while single shot methods are faster but less accurate. Newer methods like Faster R-CNN, R-FCN, YOLOv2, and SSD have improved speed and accuracy over earlier approaches.
PR-207: YOLOv3: An Incremental Improvement
PR-207: YOLOv3: An Incremental ImprovementJinwon Lee YOLOv3 makes the following incremental improvements over previous versions of YOLO:
1. It predicts bounding boxes at three different scales to detect objects more accurately at a variety of sizes.
2. It uses Darknet-53 as its feature extractor, which provides better performance than ResNet while being faster to evaluate.
3. It predicts more bounding boxes overall (over 10,000) to detect objects more precisely, as compared to YOLOv2 which predicts around 800 boxes.
Anatomy of YOLO - v1
Anatomy of YOLO - v1Jihoon Song This document provides an overview of the YOLO object detection system. YOLO frames object detection as a single regression problem to predict bounding boxes and class probabilities in one step. It divides the image into a grid where each cell predicts bounding boxes and conditional class probabilities. YOLO is very fast, processing images in real-time. However, it struggles with small objects and localization accuracy compared to methods like Fast R-CNN that have a region proposal step. Combining YOLO with Fast R-CNN can improve performance by leveraging their individual strengths.
Object detection and Instance Segmentation
Object detection and Instance SegmentationHichem Felouat The document discusses object detection and instance segmentation models like YOLOv5, Faster R-CNN, EfficientDet, Mask R-CNN, and TensorFlow's object detection API. It provides information on labeling images with bounding boxes for training these models, including open-source and commercial annotation tools. The document also covers evaluating object detection models using metrics like mean average precision (mAP) and intersection over union (IoU). It includes an example of training YOLOv5 on a custom dataset.
A Brief History of Object Detection / Tommi Kerola
A Brief History of Object Detection / Tommi KerolaPreferred Networks Object detection is an important computer vision technique with applications in several domains such as autonomous driving, personal and industrial robotics. The below slides cover the history of object detection from before deep learning until recent research. The slides aim to cover the history and future directions of object detection, as well as some guidelines for how to choose which type of object detector to use for your own project.
Yolo
YoloSourav Garai This document discusses the real-time object detection method YOLO (You Only Look Once). YOLO divides an image into grids and predicts bounding boxes and class probabilities for each grid cell. It sees the full image at once rather than using a sliding window approach. This allows it to detect objects in one pass of the neural network, making it very fast compared to other methods. YOLO is also accurate, achieving a high mean average precision. However, it can struggle to precisely localize small objects and objects that appear in dense groups.
YOLOv4: optimal speed and accuracy of object detection review
YOLOv4: optimal speed and accuracy of object detection reviewLEE HOSEONG YOLOv4 builds upon previous YOLO models and introduces techniques like CSPDarknet53, SPP, PAN, Mosaic data augmentation, and modifications to existing methods to achieve state-of-the-art object detection speed and accuracy while being trainable on a single GPU. Experiments show that combining these techniques through a "bag of freebies" and "bag of specials" approach improves classifier and detector performance over baselines on standard datasets. The paper contributes an efficient object detection model suitable for production use with limited resources.
Object Detection using Deep Neural Networks
Object Detection using Deep Neural NetworksUsman Qayyum Recent Talk at PI school covering following contents
Object Detection
Recent Architecture of Deep NN for Object Detection
Object Detection on Embedded Computers (or for edge computing)
SqueezeNet for embedded computing
TinySSD (object detection for edge computing)
Introduction to object detection
Introduction to object detectionBrodmann17 This is part 1/4 of Brodmann17 A-Z Deep Learning based Object Detection meetup given by Assaf Mushinsky
Object detection
Object detectionSomesh Vyas Object detection using opencv for detecting objects. Flow chart, Algorithm and implementation are explained.
Yolov5
Yolov5 Hochschule Bonn-Rhein-Sieg The document describes the architecture of 4 YOLOv5 object detection models of different sizes - small, medium, large, and extra large. Each model uses the same basic building blocks of focus, convolutional, and bottleneck CSP layers followed by upsampling and concatenation, but with different input channel sizes and numbers of layers to process images of different resolutions.
Yolo releases gianmaria
Yolo releases gianmariaDeep Learning Italia YOLO releases are one-stage object detection models that predict bounding boxes and class probabilities in an image using a single neural network. YOLO v1 divides the image into a grid and predicts bounding boxes and confidence scores for each grid cell. YOLO v2 improves on v1 with anchor boxes, batch normalization, and a Darknet-19 backbone network. YOLO v3 uses a Darknet-53 backbone, multi-scale feature maps, and a logistic classifier to achieve better accuracy. The YOLO models aim to perform real-time object detection with high accuracy while remaining fast and unified end-to-end models.
PR-132: SSD: Single Shot MultiBox Detector
PR-132: SSD: Single Shot MultiBox DetectorJinwon Lee SSD is a single-shot object detector that processes the entire image at once, rather than proposing regions of interest. It uses a base VGG16 network with additional convolutional layers to predict bounding boxes and class probabilities at three scales simultaneously. SSD achieves state-of-the-art accuracy while running significantly faster than two-stage detectors like Faster R-CNN. It introduces techniques like default boxes, hard negative mining, and data augmentation to address class imbalance and improve results on small objects. On PASCAL VOC 2007, SSD detects objects at 59 FPS with 74.3% mAP, comparable to Faster R-CNN but much faster.
Object detection with deep learning
Object detection with deep learningSushant Shrivastava This document discusses object detection using the Single Shot Detector (SSD) algorithm with the MobileNet V1 architecture. It begins with an introduction to object detection and a literature review of common techniques. It then describes the basic architecture of convolutional neural networks and how they are used for feature extraction in SSD. The SSD framework uses multi-scale feature maps for detection and convolutional predictors. MobileNet V1 reduces model size and complexity through depthwise separable convolutions. This allows SSD with MobileNet V1 to perform real-time object detection with reduced parameters and computations compared to other models.
SSD: Single Shot MultiBox Detector (UPC Reading Group)
SSD: Single Shot MultiBox Detector (UPC Reading Group)Universitat Politècnica de Catalunya Slides by Míriam Bellver at the UPC Reading group for the paper:
Liu, Wei, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, and Scott Reed. "SSD: Single Shot MultiBox Detector." ECCV 2016.
Full listing of papers at:
https://github.com/imatge-upc/readcv/blob/master/README.md
Deep learning based object detection basics
Deep learning based object detection basicsBrodmann17 The document discusses different approaches to object detection in images using deep learning. It begins with describing detection as classification, where an image is classified into categories for what objects are present. It then discusses approaches that involve separating detection into a classification head and localization head. The document also covers improvements like R-CNN which uses region proposals to first generate candidate object regions before running classification and bounding box regression on those regions using CNN features. This helps address issues with previous approaches like being too slow when running the CNN over the entire image at multiple locations and scales.
Real-time object detection coz YOLO!
Real-time object detection coz YOLO!J On The Beach Real-time object detection coz YOLO! by Shagufta Gurmukhdas
You Only Look Once is a state-of-the-art, high speed real-time object detection algorithm. It looks at the whole image at test time so its predictions are informed by global context in the image. This talk teaches you to develop your own application to detect and classify objects in images & videos.
1.Intro to YOLO algorithm
2. Image detection on video with YOLO
3. Processing images in Python, adding bounding boxes and labels
4. Processing complete videos in Python in the similar way as the previous section
5. Processing real time video from webcam
Object detection
Object detectionROUSHAN RAJ KUMAR Object detection is a computer technology related to computer vision and image processing that deals with detecting instances of semantic objects of a certain class (such as humans, buildings, or cars) in digital images and videos. Well-researched domains of object detection include face detection and pedestrian detection. Object detection has applications in many areas of computer vision, including image retrieval and video surveillance.
Yolo v2 ai_tech_20190421
Yolo v2 ai_tech_20190421穗碧 陳 YOLO v2 improves upon YOLO v1 in three main ways:
1. It is better by adding techniques like batch normalization, multi-scale training, and anchor boxes to improve accuracy.
2. It is faster by using a smaller input size of 416x416.
3. It is stronger by directly predicting bounding boxes rather than offsets, adding fine-grained features, and using dimensional clustering to select anchor boxes.
YOLO
YOLOgeothomas18 This document discusses the YOLO object detection algorithm and its applications in real-time object detection. YOLO frames object detection as a regression problem to predict bounding boxes and class probabilities in one pass. It can process images at 30 FPS. The document compares YOLO versions 1-3 and their improvements in small object detection, resolution, and generalization. It describes implementing YOLO with OpenCV and its use in self-driving cars due to its speed and contextual awareness.
Similar to You only look once: Unified, real-time object detection (UPC Reading Group) (6)
object-detection.pptx
object-detection.pptxMohamedAliHabib3 This document provides an overview of object detection using convolutional neural networks (CNNs). It discusses why CNNs are well-suited for object detection, defines object detection, and describes several popular CNN-based object detection algorithms including R-CNN, Fast R-CNN, Faster R-CNN, and YOLO. It also covers important object detection concepts like region proposals, sliding windows, IoU for evaluating localization accuracy, and NMS for removing overlapping detections. Open-source resources for implementing these algorithms are also provided.
Faster R-CNN: Towards real-time object detection with region proposal network...
Faster R-CNN: Towards real-time object detection with region proposal network...Universitat Politècnica de Catalunya Slides by Amaia Salvador at the UPC Computer Vision Reading Group.
Source document on GDocs with clickable links:
https://docs.google.com/presentation/d/1jDTyKTNfZBfMl8OHANZJaYxsXTqGCHMVeMeBe5o1EL0/edit?usp=sharing
Based on the original work:
Ren, Shaoqing, Kaiming He, Ross Girshick, and Jian Sun. "Faster R-CNN: Towards real-time object detection with region proposal networks." In Advances in Neural Information Processing Systems, pp. 91-99. 2015.
Top object detection algorithms in deep neural networks
Top object detection algorithms in deep neural networksApuChandraw This document discusses object detection using deep neural networks. It describes different types of neural networks including convolutional neural networks (CNNs), which are well-suited for object detection tasks. CNNs use techniques like parameter sharing and sparse connections to recognize visual patterns. Popular object detection algorithms that use CNNs are R-CNN, which proposes regions and classifies them, and YOLO (You Only Look Once), which frames detection as a single regression problem from image to bounding boxes. While very fast, YOLO struggles with small or grouped objects and unusual aspect ratios.
最近の研究情勢についていくために - Deep Learningを中心に - 
最近の研究情勢についていくために - Deep Learningを中心に - Hiroshi Fukui This document summarizes key developments in deep learning for object detection from 2012 onwards. It begins with a timeline showing that 2012 was a turning point, as deep learning achieved record-breaking results in image classification. The document then provides overviews of 250+ contributions relating to object detection frameworks, fundamental problems addressed, evaluation benchmarks and metrics, and state-of-the-art performance. Promising future research directions are also identified.
Faster R-CNN
Faster R-CNNanna8885 This document summarizes the Faster R-CNN object detection framework. It inserts a Region Proposal Network after the last convolutional layer to directly produce region proposals rather than using external proposals. The RPN classifies anchors as object or not and regresses bounding box offsets. Proposals are then fed into Fast R-CNN for classification and further regression. Experiments show Faster R-CNN achieves real-time speeds of 0.2 seconds per image while maintaining accuracy, representing a 250x speedup over R-CNN and 25x over Fast R-CNN.

Faster R-CNN: Towards real-time object detection with region proposal network...
Faster R-CNN: Towards real-time object detection with region proposal network...Universitat Politècnica de Catalunya
Ad
More from Universitat Politècnica de Catalunya (20)
Deep Generative Learning for All - The Gen AI Hype (Spring 2024)
Deep Generative Learning for All - The Gen AI Hype (Spring 2024)Universitat Politècnica de Catalunya This document provides an overview of deep generative learning and summarizes several key generative models including GANs, VAEs, diffusion models, and autoregressive models. It discusses the motivation for generative models and their applications such as image generation, text-to-image synthesis, and enhancing other media like video and speech. Example state-of-the-art models are provided for each application. The document also covers important concepts like the difference between discriminative and generative modeling, sampling techniques, and the training procedures for GANs and VAEs.
Deep Generative Learning for All
Deep Generative Learning for AllUniversitat Politècnica de Catalunya This document provides an overview of deep generative learning and summarizes several key generative models including GANs, VAEs, diffusion models, and autoregressive models. It discusses the motivation for generative models and their applications such as image generation, text-to-image synthesis, and enhancing other media like video and speech. Example state-of-the-art models are provided for each application. The document also covers important concepts like the difference between discriminative and generative modeling, sampling techniques, and the training procedures for GANs and VAEs.
The Transformer in Vision | Xavier Giro | Master in Computer Vision Barcelona...
The Transformer in Vision | Xavier Giro | Master in Computer Vision Barcelona...Universitat Politècnica de Catalunya The document discusses the Vision Transformer (ViT) model for computer vision tasks. It covers:
1. How ViT tokenizes images into patches and uses position embeddings to encode spatial relationships.
2. ViT uses a class embedding to trigger class predictions, unlike CNNs which have decoders.
3. The receptive field of ViT grows as the attention mechanism allows elements to attend to other distant elements in later layers.
4. Initial results showed ViT performance was comparable to CNNs when trained on large datasets but lagged CNNs trained on smaller datasets like ImageNet.
Towards Sign Language Translation & Production | Xavier Giro-i-Nieto
Towards Sign Language Translation & Production | Xavier Giro-i-NietoUniversitat Politècnica de Catalunya Machine translation and computer vision have greatly benefited from the advances in deep learning. A large and diverse amount of textual and visual data have been used to train neural networks whether in a supervised or self-supervised manner. Nevertheless, the convergence of the two fields in sign language translation and production still poses multiple open challenges, like the low video resources, limitations in hand pose estimation, or 3D spatial grounding from poses.
The Transformer - Xavier Giró - UPC Barcelona 2021
The Transformer - Xavier Giró - UPC Barcelona 2021Universitat Politècnica de Catalunya The transformer is the neural architecture that has received most attention in the early 2020's. It removed the recurrency in RNNs, replacing it with and attention mechanism across the input and output tokens of a sequence (cross-attenntion) and between the tokens composing the input (and output) sequences, named self-attention.
Learning Representations for Sign Language Videos - Xavier Giro - NIST TRECVI...
Learning Representations for Sign Language Videos - Xavier Giro - NIST TRECVI...Universitat Politècnica de Catalunya These slides review the research of our lab since 2016 on applied deep learning, starting from our participation in the TRECVID Instance Search 2014, moving into video analysis with CNN+RNN architectures, and our current efforts in sign language translation and production.
Open challenges in sign language translation and production
Open challenges in sign language translation and productionUniversitat Politècnica de Catalunya Machine translation and computer vision have greatly benefited of the advances in deep learning. The large and diverse amount of textual and visual data have been used to train neural networks whether in a supervised or self-supervised manner. Nevertheless, the convergence of the two field in sign language translation and production is still poses multiple open challenges, like the low video resources, limitations in hand pose estimation, or 3D spatial grounding from poses. This talk will present these challenges and the How2✌️Sign dataset (https://how2sign.github.io) recorded at CMU in collaboration with UPC, BSC, Gallaudet University and Facebook.
https://imatge.upc.edu/web/publications/sign-language-translation-and-production-multimedia-and-multimodal-challenges-all
Generation of Synthetic Referring Expressions for Object Segmentation in Videos
Generation of Synthetic Referring Expressions for Object Segmentation in VideosUniversitat Politècnica de Catalunya https://imatge-upc.github.io/synthref/
Integrating computer vision with natural language processing has achieved significant progress
over the last years owing to the continuous evolution of deep learning. A novel vision and language
task, which is tackled in the present Master thesis is referring video object segmentation, in which a
language query defines which instance to segment from a video sequence. One of the biggest chal-
lenges for this task is the lack of relatively large annotated datasets since a tremendous amount of
time and human effort is required for annotation. Moreover, existing datasets suffer from poor qual-
ity annotations in the sense that approximately one out of ten language expressions fails to uniquely
describe the target object.
The purpose of the present Master thesis is to address these challenges by proposing a novel
method for generating synthetic referring expressions for an image (video frame). This method pro-
duces synthetic referring expressions by using only the ground-truth annotations of the objects as well
as their attributes, which are detected by a state-of-the-art object detection deep neural network. One
of the advantages of the proposed method is that its formulation allows its application to any object
detection or segmentation dataset.
By using the proposed method, the first large-scale dataset with synthetic referring expressions for
video object segmentation is created, based on an existing large benchmark dataset for video instance
segmentation. A statistical analysis and comparison of the created synthetic dataset with existing ones
is also provided in the present Master thesis.
The conducted experiments on three different datasets used for referring video object segmen-
tation prove the efficiency of the generated synthetic data. More specifically, the obtained results
demonstrate that by pre-training a deep neural network with the proposed synthetic dataset one can
improve the ability of the network to generalize across different datasets, without any additional annotation cost. This outcome is even more important taking into account that no additional annotation cost is involved.
Discovery and Learning of Navigation Goals from Pixels in Minecraft
Discovery and Learning of Navigation Goals from Pixels in MinecraftUniversitat Politècnica de Catalunya Master MATT thesis defense by Juan José Nieto
Advised by Víctor Campos and Xavier Giro-i-Nieto.
27th May 2021.
Pre-training Reinforcement Learning (RL) agents in a task-agnostic manner has shown promising results. However, previous works still struggle to learn and discover meaningful skills in high-dimensional state-spaces. We approach the problem by leveraging unsupervised skill discovery and self-supervised learning of state representations. In our work, we learn a compact latent representation by making use of variational or contrastive techniques. We demonstrate that both allow learning a set of basic navigation skills by maximizing an information theoretic objective. We assess our method in Minecraft 3D maps with different complexities. Our results show that representations and conditioned policies learned from pixels are enough for toy examples, but do not scale to realistic and complex maps. We also explore alternative rewards and input observations to overcome these limitations.
https://imatge.upc.edu/web/publications/discovery-and-learning-navigation-goals-pixels-minecraft
Learn2Sign : Sign language recognition and translation using human keypoint e...
Learn2Sign : Sign language recognition and translation using human keypoint e...Universitat Politècnica de Catalunya Peter Muschick MSc thesis
Universitat Pollitecnica de Catalunya, 2020
Sign language recognition and translation has been an active research field in the recent years with most approaches using deep neural networks to extract information from sign language data. This work investigates the mostly disregarded approach of using human keypoint estimation from image and video data with OpenPose in combination with transformer network architecture. Firstly, it was shown that it is possible to recognize individual signs (4.5% word error rate (WER)). Continuous sign language recognition though was more error prone (77.3% WER) and sign language translation was not possible using the proposed methods, which might be due to low accuracy scores of human keypoint estimation by OpenPose and accompanying loss of information or insufficient capacities of the used transformer model. Results may improve with the use of datasets containing higher repetition rates of individual signs or focusing more precisely on keypoint extraction of hands.
Intepretability / Explainable AI for Deep Neural Networks
Intepretability / Explainable AI for Deep Neural NetworksUniversitat Politècnica de Catalunya This document discusses interpretability and explainable AI (XAI) in neural networks. It begins by providing motivation for why explanations of neural network predictions are often required. It then provides an overview of different interpretability techniques, including visualizing learned weights and feature maps, attribution methods like class activation maps and guided backpropagation, and feature visualization. Specific examples and applications of each technique are described. The document serves as a guide to interpretability and explainability in deep learning models.
Convolutional Neural Networks - Xavier Giro - UPC TelecomBCN Barcelona 2020
Convolutional Neural Networks - Xavier Giro - UPC TelecomBCN Barcelona 2020Universitat Politècnica de Catalunya Deep learning technologies are at the core of the current revolution in artificial intelligence for multimedia data analysis. The convergence of large-scale annotated datasets and affordable GPU hardware has allowed the training of neural networks for data analysis tasks which were previously addressed with hand-crafted features. Architectures such as convolutional neural networks, recurrent neural networks or Q-nets for reinforcement learning have shaped a brand new scenario in signal processing. This course will cover the basic principles of deep learning from both an algorithmic and computational perspectives.
Self-Supervised Audio-Visual Learning - Xavier Giro - UPC TelecomBCN Barcelon...
Self-Supervised Audio-Visual Learning - Xavier Giro - UPC TelecomBCN Barcelon...Universitat Politècnica de Catalunya Deep learning technologies are at the core of the current revolution in artificial intelligence for multimedia data analysis. The convergence of large-scale annotated datasets and affordable GPU hardware has allowed the training of neural networks for data analysis tasks which were previously addressed with hand-crafted features. Architectures such as convolutional neural networks, recurrent neural networks or Q-nets for reinforcement learning have shaped a brand new scenario in signal processing. This course will cover the basic principles of deep learning from both an algorithmic and computational perspectives.
Attention for Deep Learning - Xavier Giro - UPC TelecomBCN Barcelona 2020
Attention for Deep Learning - Xavier Giro - UPC TelecomBCN Barcelona 2020Universitat Politècnica de Catalunya Deep learning technologies are at the core of the current revolution in artificial intelligence for multimedia data analysis. The convergence of large-scale annotated datasets and affordable GPU hardware has allowed the training of neural networks for data analysis tasks which were previously addressed with hand-crafted features. Architectures such as convolutional neural networks, recurrent neural networks or Q-nets for reinforcement learning have shaped a brand new scenario in signal processing. This course will cover the basic principles of deep learning from both an algorithmic and computational perspectives.
Generative Adversarial Networks GAN - Xavier Giro - UPC TelecomBCN Barcelona ...
Generative Adversarial Networks GAN - Xavier Giro - UPC TelecomBCN Barcelona ...Universitat Politècnica de Catalunya https://telecombcn-dl.github.io/dlai-2020/
Deep learning technologies are at the core of the current revolution in artificial intelligence for multimedia data analysis. The convergence of large-scale annotated datasets and affordable GPU hardware has allowed the training of neural networks for data analysis tasks which were previously addressed with hand-crafted features. Architectures such as convolutional neural networks, recurrent neural networks or Q-nets for reinforcement learning have shaped a brand new scenario in signal processing. This course will cover the basic principles of deep learning from both an algorithmic and computational perspectives.
Q-Learning with a Neural Network - Xavier Giró - UPC Barcelona 2020
Q-Learning with a Neural Network - Xavier Giró - UPC Barcelona 2020Universitat Politècnica de Catalunya https://telecombcn-dl.github.io/drl-2020/
This course presents the principles of reinforcement learning as an artificial intelligence tool based on the interaction of the machine with its environment, with applications to control tasks (eg. robotics, autonomous driving) o decision making (eg. resource optimization in wireless communication networks). It also advances in the development of deep neural networks trained with little or no supervision, both for discriminative and generative tasks, with special attention on multimedia applications (vision, language and speech).
Language and Vision with Deep Learning - Xavier Giró - ACM ICMR 2020 (Tutorial)
Language and Vision with Deep Learning - Xavier Giró - ACM ICMR 2020 (Tutorial)Universitat Politècnica de Catalunya Giro-i-Nieto, X. One Perceptron to Rule Them All: Language, Vision, Audio and Speech. In Proceedings of the 2020 International Conference on Multimedia Retrieval (pp. 7-8).
Tutorial page:
https://imatge.upc.edu/web/publications/one-perceptron-rule-them-all-language-vision-audio-and-speech-tutorial
Deep neural networks have boosted the convergence of multimedia data analytics in a unified framework shared by practitioners in natural language, vision and speech. Image captioning, lip reading or video sonorization are some of the first applications of a new and exciting field of research exploiting the generalization properties of deep neural representation. This tutorial will firstly review the basic neural architectures to encode and decode vision, text and audio, to later review the those models that have successfully translated information across modalities.
Image Segmentation with Deep Learning - Xavier Giro & Carles Ventura - ISSonD...
Image Segmentation with Deep Learning - Xavier Giro & Carles Ventura - ISSonD...Universitat Politècnica de Catalunya This document summarizes image segmentation techniques using deep learning. It begins with an overview of semantic segmentation and instance segmentation. It then discusses several techniques for semantic segmentation, including deconvolution/transposed convolution for learnable upsampling, skip connections to combine predictions from different CNN depths, and dilated convolutions to increase the receptive field without losing resolution. For instance segmentation, it covers proposal-based methods like Mask R-CNN, and single-shot and recurrent approaches as alternatives to proposal-based models.
Curriculum Learning for Recurrent Video Object Segmentation
Curriculum Learning for Recurrent Video Object SegmentationUniversitat Politècnica de Catalunya https://imatge-upc.github.io/rvos-mots/
Video object segmentation can be understood as a sequence-to-sequence task that can benefit from the curriculum learning strategies for better and faster training of deep neural networks. This work explores different schedule sampling and frame skipping variations to significantly improve the performance of a recurrent architecture. Our results on the car class of the KITTI-MOTS challenge indicate that, surprisingly, an inverse schedule sampling is a better option than a classic forward one. Also, that a progressive skipping of frames during training is beneficial, but only when training with the ground truth masks instead of the predicted ones.
Deep Self-supervised Learning for All - Xavier Giro - X-Europe 2020
Deep Self-supervised Learning for All - Xavier Giro - X-Europe 2020Universitat Politècnica de Catalunya Deep neural networks have achieved outstanding results in various applications such as vision, language, audio, speech, or reinforcement learning. These powerful function approximators typically require large amounts of data to be trained, which poses a challenge in the usual case where little labeled data is available. During the last year, multiple solutions have been proposed to leverage this problem, based on the concept of self-supervised learning, which can be understood as a specific case of unsupervised learning. This talk will cover its basic principles and provide examples in the field of multimedia.
Deep Generative Learning for All - The Gen AI Hype (Spring 2024)
Deep Generative Learning for All - The Gen AI Hype (Spring 2024)Universitat Politècnica de Catalunya
The Transformer in Vision | Xavier Giro | Master in Computer Vision Barcelona...
The Transformer in Vision | Xavier Giro | Master in Computer Vision Barcelona...Universitat Politècnica de Catalunya
Towards Sign Language Translation & Production | Xavier Giro-i-Nieto
Towards Sign Language Translation & Production | Xavier Giro-i-NietoUniversitat Politècnica de Catalunya
Learning Representations for Sign Language Videos - Xavier Giro - NIST TRECVI...
Learning Representations for Sign Language Videos - Xavier Giro - NIST TRECVI...Universitat Politècnica de Catalunya
Generation of Synthetic Referring Expressions for Object Segmentation in Videos
Generation of Synthetic Referring Expressions for Object Segmentation in VideosUniversitat Politècnica de Catalunya
Discovery and Learning of Navigation Goals from Pixels in Minecraft
Discovery and Learning of Navigation Goals from Pixels in MinecraftUniversitat Politècnica de Catalunya
Learn2Sign : Sign language recognition and translation using human keypoint e...
Learn2Sign : Sign language recognition and translation using human keypoint e...Universitat Politècnica de Catalunya
Convolutional Neural Networks - Xavier Giro - UPC TelecomBCN Barcelona 2020
Convolutional Neural Networks - Xavier Giro - UPC TelecomBCN Barcelona 2020Universitat Politècnica de Catalunya
Self-Supervised Audio-Visual Learning - Xavier Giro - UPC TelecomBCN Barcelon...
Self-Supervised Audio-Visual Learning - Xavier Giro - UPC TelecomBCN Barcelon...Universitat Politècnica de Catalunya
Attention for Deep Learning - Xavier Giro - UPC TelecomBCN Barcelona 2020
Attention for Deep Learning - Xavier Giro - UPC TelecomBCN Barcelona 2020Universitat Politècnica de Catalunya
Generative Adversarial Networks GAN - Xavier Giro - UPC TelecomBCN Barcelona ...
Generative Adversarial Networks GAN - Xavier Giro - UPC TelecomBCN Barcelona ...Universitat Politècnica de Catalunya
Q-Learning with a Neural Network - Xavier Giró - UPC Barcelona 2020
Q-Learning with a Neural Network - Xavier Giró - UPC Barcelona 2020Universitat Politècnica de Catalunya
Language and Vision with Deep Learning - Xavier Giró - ACM ICMR 2020 (Tutorial)
Language and Vision with Deep Learning - Xavier Giró - ACM ICMR 2020 (Tutorial)Universitat Politècnica de Catalunya
Image Segmentation with Deep Learning - Xavier Giro & Carles Ventura - ISSonD...
Image Segmentation with Deep Learning - Xavier Giro & Carles Ventura - ISSonD...Universitat Politècnica de Catalunya
Deep Self-supervised Learning for All - Xavier Giro - X-Europe 2020
Deep Self-supervised Learning for All - Xavier Giro - X-Europe 2020Universitat Politècnica de Catalunya
Ad
Recently uploaded (20)
Learn the Basics of Agile Development: Your Step-by-Step Guide
Learn the Basics of Agile Development: Your Step-by-Step GuideMarcel David New to Agile? This step-by-step guide is your perfect starting point. "Learn the Basics of Agile Development" simplifies complex concepts, providing you with a clear understanding of how Agile can improve software development and project management. Discover the benefits of iterative work, team collaboration, and flexible planning.
Linux Professional Institute LPIC-1 Exam.pdf
Linux Professional Institute LPIC-1 Exam.pdfRHCSA Guru Introduction to LPIC-1 Exam - overview, exam details, price and job opportunities
Enhancing ICU Intelligence: How Our Functional Testing Enabled a Healthcare I...
Enhancing ICU Intelligence: How Our Functional Testing Enabled a Healthcare I...Impelsys Inc. Impelsys provided a robust testing solution, leveraging a risk-based and requirement-mapped approach to validate ICU Connect and CritiXpert. A well-defined test suite was developed to assess data communication, clinical data collection, transformation, and visualization across integrated devices.
Procurement Insights Cost To Value Guide.pptx
Procurement Insights Cost To Value Guide.pptxJon Hansen Procurement Insights integrated Historic Procurement Industry Archives, serves as a powerful complement — not a competitor — to other procurement industry firms. It fills critical gaps in depth, agility, and contextual insight that most traditional analyst and association models overlook.
Learn more about this value- driven proprietary service offering here.
AI EngineHost Review: Revolutionary USA Datacenter-Based Hosting with NVIDIA ...
AI EngineHost Review: Revolutionary USA Datacenter-Based Hosting with NVIDIA ...SOFTTECHHUB I started my online journey with several hosting services before stumbling upon Ai EngineHost. At first, the idea of paying one fee and getting lifetime access seemed too good to pass up. The platform is built on reliable US-based servers, ensuring your projects run at high speeds and remain safe. Let me take you step by step through its benefits and features as I explain why this hosting solution is a perfect fit for digital entrepreneurs.
Technology Trends in 2025: AI and Big Data Analytics
Technology Trends in 2025: AI and Big Data AnalyticsInData Labs At InData Labs, we have been keeping an ear to the ground, looking out for AI-enabled digital transformation trends coming our way in 2025. Our report will provide a look into the technology landscape of the future, including:
-Artificial Intelligence Market Overview
-Strategies for AI Adoption in 2025
-Anticipated drivers of AI adoption and transformative technologies
-Benefits of AI and Big data for your business
-Tips on how to prepare your business for innovation
-AI and data privacy: Strategies for securing data privacy in AI models, etc.
Download your free copy nowand implement the key findings to improve your business.

The Evolution of Meme Coins A New Era for Digital Currency ppt.pdf
The Evolution of Meme Coins A New Era for Digital Currency ppt.pdfAbi john Analyze the growth of meme coins from mere online jokes to potential assets in the digital economy. Explore the community, culture, and utility as they elevate themselves to a new era in cryptocurrency.
Leading AI Innovation As A Product Manager - Michael Jidael
Leading AI Innovation As A Product Manager - Michael JidaelMichael Jidael Unlike traditional product management, AI product leadership requires new mental models, collaborative approaches, and new measurement frameworks. This presentation breaks down how Product Managers can successfully lead AI Innovation in today's rapidly evolving technology landscape. Drawing from practical experience and industry best practices, I shared frameworks, approaches, and mindset shifts essential for product leaders navigating the unique challenges of AI product development.
In this deck, you'll discover:
- What AI leadership means for product managers
- The fundamental paradigm shift required for AI product development.
- A framework for identifying high-value AI opportunities for your products.
- How to transition from user stories to AI learning loops and hypothesis-driven development.
- The essential AI product management framework for defining, developing, and deploying intelligence.
- Technical and business metrics that matter in AI product development.
- Strategies for effective collaboration with data science and engineering teams.
- Framework for handling AI's probabilistic nature and setting stakeholder expectations.
- A real-world case study demonstrating these principles in action.
- Practical next steps to begin your AI product leadership journey.
This presentation is essential for Product Managers, aspiring PMs, product leaders, innovators, and anyone interested in understanding how to successfully build and manage AI-powered products from idea to impact. The key takeaway is that leading AI products is about creating capabilities (intelligence) that continuously improve and deliver increasing value over time.
Into The Box Conference Keynote Day 1 (ITB2025)
Into The Box Conference Keynote Day 1 (ITB2025)Ortus Solutions, Corp This is the keynote of the Into the Box conference, highlighting the release of the BoxLang JVM language, its key enhancements, and its vision for the future.
Rock, Paper, Scissors: An Apex Map Learning Journey
Rock, Paper, Scissors: An Apex Map Learning JourneyLynda Kane Slide Deck from Presentations to WITDevs (April 2021) and Cleveland Developer Group (6/28/2023) on using Rock, Paper, Scissors to learn the Map construct in Salesforce Apex development.
What is Model Context Protocol(MCP) - The new technology for communication bw...
What is Model Context Protocol(MCP) - The new technology for communication bw...Vishnu Singh Chundawat The MCP (Model Context Protocol) is a framework designed to manage context and interaction within complex systems. This SlideShare presentation will provide a detailed overview of the MCP Model, its applications, and how it plays a crucial role in improving communication and decision-making in distributed systems. We will explore the key concepts behind the protocol, including the importance of context, data management, and how this model enhances system adaptability and responsiveness. Ideal for software developers, system architects, and IT professionals, this presentation will offer valuable insights into how the MCP Model can streamline workflows, improve efficiency, and create more intuitive systems for a wide range of use cases.
Build Your Own Copilot & Agents For Devs
Build Your Own Copilot & Agents For DevsBrian McKeiver May 2nd, 2025 talk at StirTrek 2025 Conference.

Special Meetup Edition - TDX Bengaluru Meetup #52.pptx
Special Meetup Edition - TDX Bengaluru Meetup #52.pptxshyamraj55 We’re bringing the TDX energy to our community with 2 power-packed sessions:
🛠️ Workshop: MuleSoft for Agentforce
Explore the new version of our hands-on workshop featuring the latest Topic Center and API Catalog updates.
📄 Talk: Power Up Document Processing
Dive into smart automation with MuleSoft IDP, NLP, and Einstein AI for intelligent document workflows.
Cyber Awareness overview for 2025 month of security
Cyber Awareness overview for 2025 month of securityriccardosl1 Cyber awareness training educates employees on risk associated with internet and malicious emails
Big Data Analytics Quick Research Guide by Arthur Morgan
Big Data Analytics Quick Research Guide by Arthur MorganArthur Morgan This is a Quick Research Guide (QRG).
QRGs include the following:
- A brief, high-level overview of the QRG topic.
- A milestone timeline for the QRG topic.
- Links to various free online resource materials to provide a deeper dive into the QRG topic.
- Conclusion and a recommendation for at least two books available in the SJPL system on the QRG topic.
QRGs planned for the series:
- Artificial Intelligence QRG
- Quantum Computing QRG
- Big Data Analytics QRG
- Spacecraft Guidance, Navigation & Control QRG (coming 2026)
- UK Home Computing & The Birth of ARM QRG (coming 2027)
Any questions or comments?
- Please contact Arthur Morgan at [email protected].
100% human made.
Mobile App Development Company in Saudi Arabia
Mobile App Development Company in Saudi ArabiaSteve Jonas EmizenTech is a globally recognized software development company, proudly serving businesses since 2013. With over 11+ years of industry experience and a team of 200+ skilled professionals, we have successfully delivered 1200+ projects across various sectors. As a leading Mobile App Development Company In Saudi Arabia we offer end-to-end solutions for iOS, Android, and cross-platform applications. Our apps are known for their user-friendly interfaces, scalability, high performance, and strong security features. We tailor each mobile application to meet the unique needs of different industries, ensuring a seamless user experience. EmizenTech is committed to turning your vision into a powerful digital product that drives growth, innovation, and long-term success in the competitive mobile landscape of Saudi Arabia.
Rusty Waters: Elevating Lakehouses Beyond Spark
Rusty Waters: Elevating Lakehouses Beyond Sparkcarlyakerly1 Spark is a powerhouse for large datasets, but when it comes to smaller data workloads, its overhead can sometimes slow things down. What if you could achieve high performance and efficiency without the need for Spark?
At S&P Global Commodity Insights, having a complete view of global energy and commodities markets enables customers to make data-driven decisions with confidence and create long-term, sustainable value. 🌍
Explore delta-rs + CDC and how these open-source innovations power lightweight, high-performance data applications beyond Spark! 🚀

What is Model Context Protocol(MCP) - The new technology for communication bw...
What is Model Context Protocol(MCP) - The new technology for communication bw...Vishnu Singh Chundawat
You only look once: Unified, real-time object detection (UPC Reading Group)
- 1. YOLO: You Only Look Once Unified Real-Time Object Detection Slides by: Andrea Ferri For: Computer Vision Reading Group (08/03/16) Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi [Website] [Paper] [arXiv] [Reviews]
- 2. INTRODUCTION
- 3. Nowadays State of the Art approach, are so architected: Conv Layer 5 Conv layers RPN RPN Proposals RPN Proposals Class probabilities RoI pooling layer FC layers Class scores
- 4. This complex pipeline means that: Slow Pipeline Single Pipelines Hard to Optimize Need Parallel Training for Components
- 5. WHAT’S NEW? (In the architecture approach.)
- 6. Developed as Single Convolutional Network Reason Globally on the Entire Image Learns Generalizable Representations Easy & Fast Detection as Single Regression Problem Concepts
- 8. Divide the image into a SxS grid. If the center of an object fall into a grid cell, it will be the responsible for the object. Each grid cell predict: B bounding boxes; B confidence scores as C=Pr(Obj)*IOU; Confidence Prediction is obtained as IOU of predicted box and any ground truth box. C cond. Class prob. as P=Pr(𝑪𝒍𝒂𝒔𝒔𝒊|Object);
- 9. We obtain the class-specific confidence score as: Pr(𝑪𝒍𝒂𝒔𝒔𝒊|Object)*Pr(Object)*IOU = Pr(𝑪𝒍𝒂𝒔𝒔𝒊)*IOU
- 10. Design
- 11. Loss-Function
- 12. Limitations Struggle with Small Object. Loss function threats errors in different boxes ratio at the same. Struggle with Different aspects and ratios of objects. Loss function is an approximation.
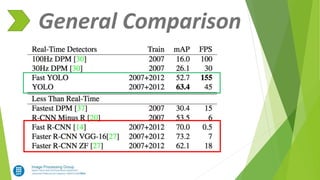
- 15. Fast R-CNN & YOLO
- 16. Fast R-CNN & YOLO Using YOLO accuracy for Big object to avoid detection mistakes into Fast R-CNN:
- 17. Fast R-CNN & YOLO
- 18. SUMMARY (Why is an interesting approach.)
- 19. The fastest general-purpose object detector in the literature. Trained on a loss function that directly corresponds to detection performance. The entire model is trained jointly. At least detection at 45fps. Pros
- 20. • You Only Look Once: Unified, Real-Time Object Detection, Joseph Redmon, Santosh Divvala, Ross Girshick, Ali Farhadi. References