Mongo db php_shaken_not_stirred_joomlafrappe
1 like1,164 views

My presentation on MongoDB at the 2nd Joomlafrappe in Athens. A short introduction to NoSQL, MongoDB Replica Sets, sharding and the PHP driver







![MongoDB | What can a value be?
• Keys are always strings (without . and $)
• Value can be
• String
• Number
• Date
• Array
• Document
{“name” : “Spyros Passas”}
{“age” : 30}
{“birthday” : Date(“1982-12-12”}
{“interests” : [“Programming”, “NoSQL”]}
{“address” : {
“street” : “123 Pireus st.”,
“city” : “Athens”,
“zip_code” : 17121
}
}
Friday, April 12, 13](https://image.slidesharecdn.com/mongodbphpshakennotstirredjoomlafrappe-130415131913-phpapp01/85/Mongo-db-php_shaken_not_stirred_joomlafrappe-8-320.jpg)
![MongoDB | Example of a document
{
“_id” : ObjectId(“47cc67093475061e3d95369d”),
“name” : “Spyros Passas”,
“birthday” : Date(“1982-12-12”),
“age” : 30,
“interests” : [“Programming”, “NoSQL”],
“address” : {
“street” : “123 Pireus st.”,
“city” : “Athens”,
“zip_code” : 17121
}
“_id” : ObjectId(“47cc67093475061e3d95369d”)
ObjectId is a special type
Friday, April 12, 13](https://image.slidesharecdn.com/mongodbphpshakennotstirredjoomlafrappe-130415131913-phpapp01/85/Mongo-db-php_shaken_not_stirred_joomlafrappe-9-320.jpg)
































![Elasticsearch And Ruby [RuPy2012]](https://cdn.slidesharecdn.com/ss_thumbnails/elasticsearchandruby-karelminarik-rupy2012-121118065224-phpapp01-thumbnail.jpg?width=560&fit=bounds)























More Related Content
What's hot (20)
Viewers also liked (6)




Similar to Mongo db php_shaken_not_stirred_joomlafrappe (20)




















Recently uploaded (20)




















Mongo db php_shaken_not_stirred_joomlafrappe
- 1. PHP & MongoDB Shaken, not stirred Spyros Passas / @spassas Friday, April 12, 13
- 2. NoSQL | Everybody is talking about it! Friday, April 12, 13
- 3. NoSQL | What • NoSQL ≠ SQL is dead • Not an opposite, but an alternative/complement to SQL (Not Only SQL) • Came as a need for large volumes of data and high transaction rates • Are generally based on key/value store • Are very happy with denormalized data since they have no joins Friday, April 12, 13
- 4. NoSQL | Why • Flexible Data Model, so no prototyping is needed • Scaling out instead of Scaling up • Performance is significantly higher • Cheaper licenses (or free) • Runs on commodity hardware • Caching layer already there • Data variety Friday, April 12, 13
- 5. NoSQL | Why not • well, it’s not all ACID... • Less mature than the relational systems (so the ecosystem of tools/addons is still small) • BI & Reporting is limited • Coarse grained Security settings Friday, April 12, 13
- 6. NoSQL | Which • Key/Value stores • Document Databases • And more... Friday, April 12, 13
- 7. MongoDB | Documents & Collections • Document is the equivalent of an SQL table row and is a set of key/value pairs • Collection is the equivalent of an SQL table and is a set of documents not necessarily of the same type • Database is the equivalent of a... database { “name” : “Spyros Passas”, “company” : “Neybox” } { “name” : “Spyros Passas”, “company” : “Neybox” } { “Event” : “JoomlaFrappe”, “location” : “Athens” } Friday, April 12, 13
- 8. MongoDB | What can a value be? • Keys are always strings (without . and $) • Value can be • String • Number • Date • Array • Document {“name” : “Spyros Passas”} {“age” : 30} {“birthday” : Date(“1982-12-12”} {“interests” : [“Programming”, “NoSQL”]} {“address” : { “street” : “123 Pireus st.”, “city” : “Athens”, “zip_code” : 17121 } } Friday, April 12, 13
- 9. MongoDB | Example of a document { “_id” : ObjectId(“47cc67093475061e3d95369d”), “name” : “Spyros Passas”, “birthday” : Date(“1982-12-12”), “age” : 30, “interests” : [“Programming”, “NoSQL”], “address” : { “street” : “123 Pireus st.”, “city” : “Athens”, “zip_code” : 17121 } “_id” : ObjectId(“47cc67093475061e3d95369d”) ObjectId is a special type Friday, April 12, 13
- 10. MongoDB | Indexes • Any field can be indexed • Indexes are ordered • Indexes can be unique • Compound indexes are possible (and in fact very useful) • Can be created or dropped at anytime • Indexes have a large size and an insertion overhead Friday, April 12, 13
- 11. MongoDB | Operators & Modifiers • Comparison: $lt (<), $lte (<=), $ne (!=), $gte (>=), $gt (>) • Logical: $and, $or, $not, $nor • Array: $all, $in, $nin • Geospatial: $geoWithin, $geoIntersects, $near, $nearSphere • Fields: $inc, $rename, $set, $unset • Array: $pop, $pull, $push, $addToSet Friday, April 12, 13
- 12. MongoDB | Data Relations • MongoDB has no joins (but you can fake them in the application level) • MongoDB supports nested data (and it’s a pretty good idea actually!) • Collections are not necessary, but greatly help data organization and performance Friday, April 12, 13
- 13. MongoDB | Going from relational to NoSQL • Rethink your data and select a proper database • Rethink the relationships between your data • Rethink your query access patterns to create efficient indexes • Get to know your NoSQL database (and its limitations) • Move logic from data to application layer (but be careful) Friday, April 12, 13
- 14. MongoDB | Deployment Mongo Server Data Layer Application Layer App Server + mongos Friday, April 12, 13
- 15. MongoDB | Deployment Mongo Server Friday, April 12, 13
- 16. MongoDB | Replica Set Primary (Master) Secondary (Slave) Friday, April 12, 13
- 17. MongoDB | Replica Set Primary (Master) Secondary (Slave)Secondary (Slave) Secondary (Slave) Friday, April 12, 13
- 18. MongoDB | Replica Set when things go wrong Primary (Master) Secondary (Slave)Secondary (Slave) Secondary (Slave) Friday, April 12, 13
- 19. MongoDB | Replica Set when things go wrong Primary (Master) Secondary (Slave) Secondary (Slave) Friday, April 12, 13
- 20. MongoDB | Replica Set when things go wrong Primary (Master) Secondary (Slave) Secondary (Slave)Secondary (Slave) Friday, April 12, 13
- 21. MongoDB | Replica set tips • Physical machines should be in independent availability zones • Selecting to read from slaves significantly increases performance (but you have to be cautious) Friday, April 12, 13
- 22. MongoDB | Sharding A...Z Friday, April 12, 13
- 23. MongoDB | Sharding A...J K....P Q....Z Friday, April 12, 13
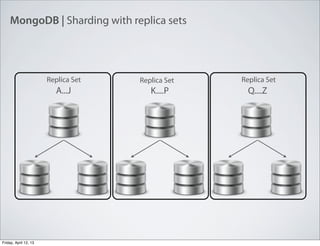
- 24. MongoDB | Sharding with replica sets A...J K....P Q....Z Replica SetReplica SetReplica Set Friday, April 12, 13
- 25. MongoDB | Sharding with replica sets A...J K....P Q....Z Config Servers Replica SetReplica SetReplica Set Friday, April 12, 13
- 26. MongoDB | Things to consider when sharding • Picking the right sharding key is of paramount importance! • Rule of thumb:“the shard key must distribute reads and writes and keep the data you’re using together” • Key must be of high cardinality • Key must not be monotonically ascending to infinity • Key must not be random • A good idea is a coarsely ascending field + a field you query a lot Friday, April 12, 13
- 27. MongoDB | PHP | The driver • Serializes objects to BSON • Uses exceptions to handle errors • Core classes • MongoClient: Creates and manages DB connections • MongoDB: Interact with a database • MongoCollection: Represents and manages a collection • MongoCursor: Used to iterate through query results Friday, April 12, 13
- 28. MongoDB | PHP | MongoClient <?php // Gets the client $mongo = new MongoClient(“mongodb://localhost:27017”); // Sets the read preferences (Primary only or primary & secondary) $mongo->setReadPreference(MongoClient::RP_SECONDARY); // If in replica set, returns hosts status $hosts_array = mongo->getHosts(); // Returns an array with the database names $db_array = $mongo->listDBs(); // Returns a MongoDB object $database = $mongo->selectDB(“myblog”); ?> Creates a connection and sets read preferences Provide info about hosts status and health Lists, selects or drops databases Friday, April 12, 13
- 29. MongoDB | PHP | MongoDB <?php // Create a collection $database->createCollection(“blogposts”); // Select a collection $blogCollection = $database->selectCollection(“blogposts”); // Drop a collection $database->dropCollection(“blogposts”) ?> Handles Collections Friday, April 12, 13
- 30. MongoDB | PHP | MongoCollection | Insert <?php // Fire and forget insertion $properties = array(“author”=>”spassas”, “title”=>”Hello World”); $collection->insert($properties); ?> Insert <?php // Safe insertion $properties = array(“author”=>”spassas”, “title”=>”Hello World”); $collection->insert($properties, array(“safe”=>true)); ?> Friday, April 12, 13
- 31. MongoDB | PHP | MongoCollection | Update <?php // Update $c->insert(array("firstname" => "Spyros", "lastname" => "Passas" )); $newdata = array('$set' => array("address" => "123 Pireos st")); $c->update(array("firstname" => "Spyros"), $newdata); // Upsert $c->update( array("uri" => "/summer_pics"), array('$inc' => array("page_hits" => 1)), array("upsert" => true) ); ?> Friday, April 12, 13
- 32. MongoDB | PHP | MongoCollection | Delete <?php // Delete parameters $keyValue = array(“name” => “Spyros”); // Safe remove $collection->remove($keyValue, array('safe' => true)); // Fire and forget remove $collection->remove($keyValue); ?> Friday, April 12, 13
- 33. MongoDB | PHP | MongoCollection | Query <?php // Get the collection $posts = $mongo->selectDB(“blog”)->selectCollection(“posts”); // Find one $post = $posts->findOne(array('author' => 'john'), array('title')); // Find many $allPosts = $posts->find(array('author' => 'john')); // Find using operators $commentedPosts = $posts->find(array(‘comment_count’ => array(‘$gt’=>1))); // Find in arrays $tags = array(‘technology’, ‘nosql’); // Find any $postsWithAnyTag = $posts->find(array('tags' => array('$in' => $tags))); // Find all $postsWithAllTags = $posts->find(array('tags' => array('$all' => $tags))); ?> Friday, April 12, 13
- 34. MongoDB | PHP | MongoCursor <?php // Iterate through results $results = $collection->find(); foreach ($results as $result) { // Do something here } // Sort $posts = $posts->sort(array('created_at'=> -1)); // Skip a number of results $posts = $posts->skip(5); // Limit the number of results $posts = $posts->limit(10); // Chaining $posts->sort(array('created_at'=> -1))->skip(5)->limit(10); ?> Friday, April 12, 13
- 35. MongoDB | PHP | Query monitoring & Optimization explain() Gives data about index performance for a specific query { "n" : <num>, /* Number documents that match the query */ "nscannedObjects" : <num>, /* total number of documents scanned during the query */ "nscanned" : <num>, /* total number of documents and index entries */ "millis" : <num>, /* time to complete the query in milliseconds */ “millisShardTotal” : <num> /* total time to complete the query on shards */ “millisShardAvg” : <num> /* average time to complete the query on each shard */ } Friday, April 12, 13
- 36. Thank you! {“status” : “over and out”, “mood” : “:)”, “coming_up” : “Q & A” “contact_details”: { “email”:“[email protected]”, “twitter”:”@spassas”, } } Friday, April 12, 13